Informatierotonde voor semantische interoperabiliteit
Pieter Wisse
Metafoor
In het verkeer van fysieke verplaatsingen over de weg is een rotonde een
voorziening voor vlottere verbindingen. Het lijkt soms een òmweg, maar de
gestandaardiseerde manier van in- respectievelijk uitvoegen levert per saldo
voordeel voor dóórstroming.
Hier dient de traditionele verkeersrotonde als metafoor voor een extra
voorziening ter facilitering van verbindingen tussen zgn informatiesystemen.
Een informatierotonde, dus. Voorrang verkrijgt borging van sporende betekenis:
semantische interoperabiliteit.
Met deze metafoor gaat het vooral om een eerste zetje in een productieve(re)
ontwerprichting. Voor een bruikbare voorziening verdient natuurlijk juist
aandacht wat wezenlijk voor succesvol informatieverkeer is: verzonden
informatie komt vlot aan, resulterend in interpretatie tot passende betekenis.
Stel, twee bestáánde informatieverzamelingen
Wat semantische interoperabiliteit zoal inhoudt, laat zich al aardig
illustreren met een ènkele organisatie die voor haar interne bedrijfsvoering
twee informatiesystemen gebruikt. De reële veronderstelling luidt voorts, dat
die systemen (lees ook: toepassingen) ooit apàrt opgezet zijn enzovoort. Daar
horen netzo aparte informatieverzamelingen bij. Maar de informatie die in beide
systemen annex bijbehorende verzamelingen geregistreerd staat, vertoont overlap
(lees ook: duplicatie).
Er kunnen allerlei argumenten aangevoerd worden om (vooralsnog) weinig tot
niets aan die bestáánde informatieverzamelingen en bijgevolg –systemen te
veranderen. Hoe wordt desondanks (meer) samenhang bereikt? Dan ligt het voor de
hand om bepaalde informatie voortaan slechts in één verzameling als het ware
origineel op te nemen, waarna een afschrift ervan beschikbaar gesteld wordt aan
de àndere verzameling.
Waarom werkt zo’n recht-toe-recht-aan verbinding vaak echter niet?
Een reden is, dat informatie nooit zgn atomair is. Specifieke informatie heeft
daarentegen een structurele positie, zeg maar haar context. Gelijkluidende
namen, daarop wees Aristoteles reeds uitdrukkelijk, borgen daarom nog lang niet
dat contexten stroken. (Grotere) zekerheid over betekenis vergt explicitering
van bijbehorende contexten.
Aangezien contexten vergaand impliciet zijn in de apàrt opgezette systemen/toepassingen
en de afspraak hier even is om ze qua opzet ongemoeid te laten, is een
gestructureerde voorziening ertùssen nodig.
Een nauw verwante reden dat informatieuitwisseling tussen oorspronkelijk
gescheiden systemen/verzamelingen als regel een èxtra voorziening vergt, heeft
met relevante objectenpopulaties te maken. Zonder expliciete contexten heeft
het er gauw weg van, dat de ene verzameling informatie bevat over dezèlfde
objecten als de andere verzameling doet. Wie vervolgens naar relevante exemplaren
kijkt, herkent wellicht dat het ene systeem ‘gaat’ over méér exemplaren, of
juist over minder dan het andere systeem.
Wat aldus in eerste aanleg een kwantitatief vraagstuk lijkt, verkrijgt een
kwalitatieve oplossing dankzij zgn contextuele verbijzondering.
Het helpt om de illustratie iets te concretiseren. Voor organisatie x moeten
bijvoorbeeld de systemen A. relatiebeheer en B. personeelsbeheer zoveel
mogelijk intact blijven.
Er geldt dat elk personeelslid tevens ‘relatie’ van de organisatie in kwestie
is. Andersom is dat (natuurlijk) niet zo; de organisatie kent stellig méér
‘relaties’ dan personeelsleden.
Neem aan dat beide systemen c.q. verzamelingen specifieke informatie onder de
noemer van persoon kennen. In (verzameling) A betekent persoon dus
persoon-als-relatie, terwijl in (verzameling) B persoon echter
persoon-als-personeelslid betekent.
Hoe lukt het, dat A slechts persoonsinformatie aanbiedt over wat telt voor B,
dwz personeelsleden? Van oudsher wordt daarvoor in A de relatie getypeerd; als
eigenschap van relatie verschijnt daar eventueel personeelslid. Dat dient in A
als selectiecriterium voor de beoogde afschriften voor B.
Het kan ook anders(om). In B wordt slechts informatie opgegeven, waarmee een
‘relatie’ in A eenduidig valt te identificeren. Noem het gemakshalve een
relatienummer. Op basis van dat nummer kan A vervolgens een afschrift opstellen
voor B.
Intermezzo: basisregistraties
Voor de (Nederlandse) elektronische overheid zou A als een basisregistratie
tellen. Het idee is onder meer, dat B hoogstens dezelfde objectenverzameling
betreft, nooit een grotere, maar vrijwel altijd een kleinere.
Er zijn ruwweg twee soorten afschriftabonnementen. Volgens het ene ‘duwt’ A
informatie naar B over alle objecten die voldoen aan bepaalde criteria. En
volgens het andere ‘trekt’ B op basis van uniek identificerende informatie
(lees: een objectnummer) uit A (verdere) informatie over een specifiek object.
Een reden waarom dat zo niet soepel werkt, is herleidbaar tot relevante
objectenpopulaties (zoals de vorige paragraaf al aanstipte). Het blijkt dat
basisregistraties niet voldoen aan de voorwaarde dat de respectievelijke
populaties waarover informatie bijgehouden wordt, groter-of-gelijk zijn
vergeleken met informatieverzamelingen die eruit moeten putten.
Voor nadere analyse met schets van oplossingsrichting zie o.a. mijn opstellen Willen
de èchte basisregistraties …? (2009) en Basispuzzel met stelselmatige
registerstukjes (in: PrimaVera, working
paper 2009-03, Universiteit van Amsterdam, 2009). Zie ook Semantiek op stelselschaal: issues en oplossingsrichtingen (Bureau Forum
Standaardisatie, 2009).
Weliswaar minimale wijzigingen, maar tòch!
Als uitgangspunt voor deze eerste illustratie van semantische
interoperabiliteit geldt dat bestáánde informatieverzamelingen zo mogelijk ongemoeid
blijven. Met een directe voorziening tussen A en B blijkt dat niet haalbaar.
Enerzijds moet A voorzien in (selectie)criteria voor B, anderzijds moet B
voorzien in unieke objectidentificatie volgens A.
Voor een beperkt aantal informatieverzamelingen blijft dat redelijk
overzichtelijk. De schaalbaarheid van één-op-één voorzieningen is echter
problematisch. Neem het geval dat A niet de populatiedekking biedt die voor B
telt. Dan kan B voor ‘trekken’ niet volstaan met een objectidentificatie die
weliswaar voor één van de bronnen (uniek) klopt, maar voor welke precies?
Bij meerdere bronnen gaat het dus om de combinatie van objectidentificatie èn
concrete bron (An). Die opzet verdient overigens tevens de voorkeur,
als er slechts één bron benut wordt. Dat worden er met schaalvergroting van
informatieverkeer vroeg of laat méér.
Aanzet tot informatierotonde
Een informatierotonde maakt de koppeling tussen informatieverzamelingen A en
B los(ser). Om bij het voorbeeld te blijven, wanneer A dient als bron van afschriften
voor B is het voor een robuuste informatierotonde nodig om te erkennen dat
personen à la A blijkbaar ‘relaties’ zijn. Sterker nog, dat zijn geen
‘relaties’ in algemene zin, maar gelden als zodanig vàn organisatie x.
Dergelijke contextualisering valt methodisch te modelleren. Die methode heet
metapatroon (P.E. Wisse, Metapattern: context and time
in information models, Addison-Wesley, 2001) en is door Forum
Standaardisatie erkend vanwege haar mogelijkheden voor beheersing van
betekenissenvariëteit (lees ook: semantische interoperabiliteit) op
maatschappelijke, dus open schaal (lees ook, naar analogie met planologie:
door-de-schalen-heen). Zo zijn onder auspiciën van Forum Standaardisatie (www.forumstandaardisatie.nl)
diverse publicaties verschenen, zoals Semantiek op stelselschaal (2009), Analyse
van gerelateerdengegevens in het kader van RNI met Toekomstbeeld: herordening van basisregistraties (2009) als een bijlage en Praktijkmodellering
van het begrip werkgever met Modellering werkgeversbegrip (2009) als een bijlage.
Figuur 1 schetst de informatierotonde en toont voor informatietypen hoe
personen uit A (pas) ‘op’ de rotonde (tevens) expliciet als ‘relaties’ van x
bekend zijn.
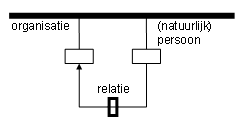
figuur 1: informatieverkeer draait om expliciete contexten.
De invalshoek volgens B laat zich met metapatroon eenvoudig aan de informatierotonde toevoegen. Dat kan zoals figuur 2.a schetst, mits de voorwaarde stand houdt dat een personeelslid van organisatie x tevens ‘relatie’ is. Zo niet, dan is het model volgens figuur 2.b nodig. Merk op dat informatieverkeer naar B niet louter vanuit A verloopt; kennelijk zijn er ook àndere bronnen met persoonsinformatie over personeelsleden. Figuur 2.b is dus toekomstvaster en verdient daarom de voorkeur.
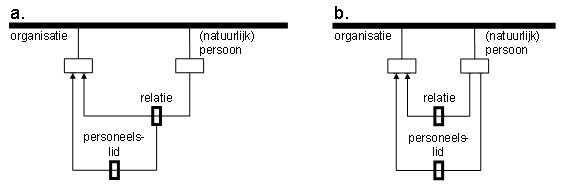
figuur 2: Hoe verhouden personeelsleden zich tot relaties?
Het effect van zo’n informatierotonde is dat A niets meer over B hoeft te
weten, B omgekeerd evenmin iets over A, enzovoort.
Stel nog steeds dat A als bron van persoonsinformatie gebruikt wordt. Wat
vanuit A feitelijk de informatierotonde bereikt, is informatie over een
persoon-als-relatie. Daarvan leidt de informatierotonde het bestaan van een
(natuurlijk) persoon y àf. Uitgaande van wat die informatie in A betekent, kan
daaraan in de informatierotonde ‘relatie’ worden toegevoegd door een … relatie
tussen persoon(exemplaar) y en organisatie(exemplaar) x. Volgens figuur 2.b
kan, indien van toepassing, in de informatierotonde tussen persoon(exemplaar) y
en organisatie(exemplaar) x vervolgens een àndere (informatie)relatie worden
gevestigd, te weten personeelslid. Dàt vormt het aanknopingspunt voor een
verdere etappe in het informatieverkeer, ditmaal van de informatierotonde naar
B.
Rotonde als register?
De mate waarin de informatierotonde tevens informatieverzameling is dan wel
moet zijn, hangt af van daadwerkelijk vraag en aanbod van informatieverkeer.
Contingent, met andere woorden.
De kaalste opzet blijft beperkt tot unieke identificaties van objecten, met
daartussen zonodig aanvullende relaties, relaties tussen zulke relaties
enzovoort ter eenduidige contextualisering. Dat volstaat, nogmaals, zolang aan
de voorwaarde voldaan is dat een specifieke vragende informatieverzameling
steeds ‘genoeg heeft’ aan informatie in één ènkele aanbiedende verzameling.
Hoe ruimer de schaal van het informatieverkeer, des te lastiger valt die
voorwaarde te borgen. Het is daarom verstandig, zo niet noodzakelijk, om te
rekenen met diverse verzamelingen als evenzovele bronnen voor informatie over
objecten van dezelfde soort. Pèr bron is bepaalde objectinformatie beschikbaar;
daarover geeft het desbetreffende informatieprofiel uitsluitsel. Zo’n profiel
is eigenlijk de gepubliceerde informatiedienst van de bron/verzameling in
kwestie.
Een sterk veralgemeniseerd model voor een rotonde ziet er dan uit zoals figuur
3.
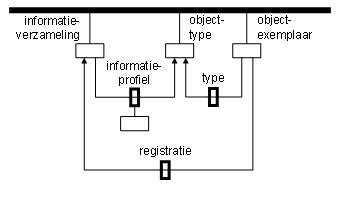
figuur 3: objectinformatie in diverse verzamelingen volgens (stellig) afwijkende profielen.
Nota bene, volgens figuur 3 kent de informatierotonde ‘eigen’ unieke
identificaties voor objectexemplaren. De identificatie die zo’n objectexemplaar
volgens een bepaalde informatieverzameling kent, staat náder contextueel
verbijzonderd vermeld in de rotonde, te weten ‘onder’ registratie. Voor iemand
(objectexemplaar) die in de Gemeentelijke Basisregistratie Persoonsgegevens
(informatieverzameling: GBA) is opgenomen, heet de desbetreffende unieke
objectidentificatie (tegenwoordig) burgerservicenummer. Een persoon (objectexemplaar)
die als klant van een winkelbedrijf geregistreerd staat
(informatieverzameling), staat daar met een klantnummer oid bekend.
In België moet aan de zgn Kruispuntbank — niet toevallig eveneens een
verkeersmetafoor — een basisidee ten grondslag liggen, dat figuur 3
ongetwijfeld benadert.
Ontoereikende informatieprofielen, tekortschietende structuur
Als factor die leidt tot vulling van de rotonde, passeerde reeds impliciete
context de revue. De noodzakelijke contextuele explicitering, in figuur 2
rudimentair getoond, illustreert dat extra informatie in de rotonde zèlf
opgenomen wordt, waardoor zij in sterkere mate tevens als register dient.
Druk in diezelfde richting groeit extra, naarmate bestáánde
informatieverzamelingen structureel niet toegerust blijken voor verander(en)de
opgaven. Zo voldeed een verouderd informatiesysteem voor personeelsbeheer
vroeger vooral als sluis naar een (veelal) extern systeem voor
salarisverwerking. Toen had een werknemer als regel precies één functie bij
haar/zijn werkgever. Verder wijzigde de organisatiestructuur van die werkgever
niet of nauwelijks.
Dat is inmiddels met deeltijdbanen, projectwerk, reorganisaties, inzet van
zzp-ers enzovoort allemaal anders. Het komt dus voor, redelijk neutraal
uitgedrukt, dat een bestáánd informatiesysteem voor personeelsbeheer daarop
niet berekend is. Dat blijkt ook niet aanpasbaar zonder gevaar van ontwrichting
van allerlei organisatorische procedures.
Indien een informatierotonde wèl voorziet in gewenste mogelijkheden, hoeft het nog
niet zo gek te zijn om het als register uit te breiden. Dat kan het aparte
systeem voor personeelsbeheer (sterk) ontlasten. De vraag is natuurlijk wel of
het niet paradoxaal is om een voorziening voor optimaler verloop van
informatieverkeer te benutten voor … terugdringen van verkeer. Op
maatschappelijke schaal (lees: elektronische overheid) moeten één of meer
informatierotondes vooral schakelen tussen (andere) registers. Dat faciliteert
de federatieve opzet respectievelijk het inherente netwerkkarakter van openbaar
bestuur. Voor een aparte organisatie speelt dat (vooralsnog) minder of helemaal
niet. Via een flexibele rotonde annex register laten zich daar gauwer
beperkingen van bestáánde informatiesystemen/-verzamelingen omzeilen.
Naar bevindt van zaken: groeipad
Een informatierotonde staat er niet compleet op korte termijn. Sterker nog,
op de schaal waarop zo’n rotonde voordeel biedt, kan zij nooit àf zijn. Door
veranderende omstandigheden veranderen behoeften aan informatieverkeer méé.
Een informatierotonde moet dus een open concept zijn. Er moet steeds een
productief vervolg aan gegeven kunnen worden, terwijl wat er reeds staat zo
toekomstvast mogelijk is.
Op toekomstvastheid wijzen resultaten van onderzoekprojecten die onder
auspiciën van Forum Standaardisatie uitgevoerd zijn. Hierboven staan enkele
publicaties opgesomd. Daaruit doemt convergentie op van betekenissenstructuur
aan de zgn modelhorizon. Die blijkt, kortom, nogal invariant en verdient daarom
de aanduiding van semantische hoofdstructuur.
Een informatierotonde die voortborduurt op bedoelde semantische hoofdstructuur
is meteen behoorlijk op weg in de goede richting. Dan moet er praktisch een
keuze volgen tussen welke informatieverzamelingen het verkeer allereerst
gestroomlijnd wordt. Daarvoor bestaat geen recept. Met het accent op interne
bedrijfsvoering, zoals hier ter illustratie aangenomen, ligt het inderdaad voor
de hand om te beginnen met uitwisseling van persoonsinformatie. Daar zit meteen
het aspect van organisatie aan vast. Dat zal meteen duidelijkheid geven, of de
rotonde tevens (verdergaand) als register gaat dienen.
Op die manier moeten alle bestaande informatieverzamelingen aan de beurt komen.
Als de volgorde met enig overzicht bepaald is, vergt elke vòlgende
verkeersstroom steeds minder werk aan de informatierotonde. Dat is natuurlijk
ook precies de bedoeling met zulke infrastructurele voorzieningen. Zie ook Schakelpaneel
(2006).
Een bijzonder aandachtspunt is beveiliging. Omdat een informatierotonde vlotte
doorstroming van informatieverkeer moet bevorderen, werkt het averechts om ter
beveiliging zoiets als een muur òm de rotonde te plaatsen. Onderdeel van een
informatierotonde is daarom eveneens het concept om niet langer de
verwerkingsmiddelen, maar informatie zèlf te beveiligen. Dat vergt betrouwbare
authenticatie en gerichte autorisatie. Daaraan zijn zonodig certificaten voor
ver- en ontsleuteling van specifieke informatie gekoppeld.
Als onderdeel van informatieverkeer geldt trouwens nadrukkelijk ook rapportage.
Een vroeg doel met rapportages dat de rotonde kan/moet dienen, is analyse. Zo
suggereert figuur 3 dat via de rotonde informatie kan worden bijeengebracht die
in verschillende verzamelingen over persoon y geregistreerd staat. Wat zijn daartussen
reële verschillen? Welke verschillen zijn daarentegen contraproductief en
vergen extra inspanningen om afgestemd te krijgen? Kunnen nodeloze verschillen
worden geëlimineerd? Dat lukt bijvoorbeeld in eerste aanleg door replicatie en
op wat langere termijn door herinrichting van informatieverzamelingen, nota
bene inclusief het beheer ervan, omdat een rotonde ze voortaan structureel kan
laten samenhangen.
25 maart 2010, webeditie 2010 © Pieter Wisse