How so-called core components are missing the point
Pieter Wisse
Part I
Context happens!
Structural comparison
Upon learning about the project to develop a Unified Context Methodology,[1]
I contacted the project chair and suggested that Metapattern be considered.[2]
What follows here is my attempt to support my suggestion in more detail.
I offered to compare Metapattern to what had so far been planned as a Unified
Context Methodology. From Requirement List for UCM,[3]
I hoped it might be simple ...
However, it didn’t take long for me to realize that comparison is far from
straightforward. The reason is that up to the respective ontologies differ. Not
only are basic concepts different but also, and essentially so, how they are
related, that is, their structures as a whole vary.
Positioning UCM
The United Nations includes so-called bodies. One such UN body is the Centre
for Trade Facilitation and Electronic Business (UN/CEFACT).
The Centre’s mission involves “facilitating national and international transactions,
through the simplification and harmonisation of processes, procedures and
information flows, and so contribute to the growth of global commerce.”[4] It
aims to “secure[…] coherence in the development of Standards and
Recommendations by co-operating with other interested parties, including
international, intergovernmental and non-governmental organizations.”[5]
The Centre “is drawing up the next generation of trade facilitation and
e-business standards and tools.”[6] This is the particular concern of one of
its five Permanent Working Groups, in this case the Techniques and
Methodologies Group (TMG).[7]
TMG includes the Core Components Working Group (CCWG) which, in turn, includes
three projects:[8]
— Core Components Technical Specification (CCTS)
— Core Components Message Assembly (CCMA)
— Unified Context Methodology (UCM).
TMG’s Business Process Working Group hosts several projects on the closely
related subject of UN/CEFACT Modeling Methodology (UMM).[9]
Between the projects of the Core Components Working Group, the Core Components
Technical Specification is considered (most) fundamental. For it is assumed for
the Core Components Message Assembly that it will be developed “based on the
use of both the UN/CEFACT Modeling Methodology (UMM) and the Core Components
Technical Specification (CCTS).”[10] Likewise, the Unified Context Methodology
“will start from the current context mechanism described in the Core Components
Technical Specification (CCTS).”[11]
Opposite concepts: core component vs. nil identity
A summary of comparing UCM to Metapattern could read that they start from
opposite concepts of what counts as (a) core component. In fact, UCM’s concept
of core component lies outside its own range. As already mentioned, with CCTS a
separate specification was developed for core components.
Metapattern can only be compared to UCM when CCTS’s concept of core component
is properly understood.[12]
At least how I understand what a core component is according to CCTS, the label
“core” seems confusing. From a core component (one or more) specific business
information entities may be derived. A particular business information entity
is some refinement of a particular core component. Such derivations,
respectively refinements vary with what is considered business context.
What I cannot recognize is what makes such a core component different from,
say, a reference object (or, indeed, a super class).
Anyway, what I really want to point out here is that such a concept, whether it
is called a core component, a reference object, or whatever, squarely fits
within the Platonic tradition. A Platonic form, however, is impossible to
instantiate. That should already be a warning.
How CCTS conceives of a core component also reminds me somewhat of Buchler’s
concept of contour. Again, an essential difference remains, though. A contour
is the set of an object’s ordinal locations, rather than the general reference
from which such locations may be derived.[13]
Yet, that seems the requirement for contextual differentiation according to
CCTS, and subsequently ‘only’ to be improved by UCM. Before some (business)
context may be applied, a core component must be equipped with the necessary
properties. Otherwise, derivation, refinement or constraints don’t yield the
appropriate business information entity.
In my view, rather than a core, such a component is actually a repository.
Metapattern is radically different. Context is not a mechanism that is applied
on a context-independent, that is, overall object. Context does not happen,
say, after the fact of establishing such a reference object.
On the contrary, information is contextual in principle. Nothing is derived in
the sense of CCTS. For some object, contextual specifications are juxtaposed.
Of course, some mechanism for relating between one object’s different
contextual specification must be provided. Metapattern’s invention is to only
share the object’s identification between relevant contexts. It is,
mathematically speaking, the necessary and sufficient condition for structure.
Another mathematically inspired idea is to apply contextual differentiation to
the object’s identification, too. The result is universality of method. The
identification itself resides in a nil context. It is a boundary concept, just
as zero has been included in the set of numbers.
For Metapattern, the label “core” does not occur. But what acts as core, I
repeat, is an object’s nil identity. Please note, as nil identity, in a nil
context, it is otherwise devoid of any specification. Only such a radical
concept of identity provides requisite variety with optimal efficiency.[14]
Occam’s razor
Not just the concept of core component that UCM takes from CCTS differs from
Metapattern’s nil identity. Other concepts are essentially related
respectively, yielding completely different conceptual structures. The previous
section supplies an illustration. An exhaustive treatment lies beyond the scope
of my comparison, here.[15]
My conclusion is that it is impossible to align UCM with Metapattern as long as
CCTS supplies the detailed frame of reference for UCM.
My fundamental criticism, therefore, concerns the Core Components Technical
Specification (CCTS) as it currently stands. Its ontology is first of all
largely implicit, which certainly doesn’t help to optimize assumptions.
Applying Occam’s razor to CCTS is not enough to eliminate redundancy. An
altogether different paradigm is required. I am far too modest to suggest that
Metapattern is the final answer to controlling information variety. But I am
also realistic. Metapattern involves a paradigm shift to eliminate assumptions
that have become counterproductive at the emerging scale of global, instant
information interconnectivity.
Of course there’s always room for improvement. Still, so far wielding Occam’s
razor for optimizing Metapattern has already resulted in fewer (basic)
assumptions. Metapattern’s assumptions emphasize variability. It directly
translates to flexibility.
An example is that Metapattern does not distinguish between core components on
the one side and business information entities on the other. Contextualization
the Metapattern way is not achieved through derivation or whatever, thus
requiring a source entity. Its assumption of distinct, i.e. non-overlapping
specifications for relevant contexts does away with such a requirement. The
contextual object immediately is the object … in that context. A nil identity
provides for connection between contexts, fundamentally combating redundancy,
thereby optimizing reuse.
Another example is the absence in Metapattern of the formal distinction between
aggregate and basic. Both context and specification are relative, whereas it
seems that only aggregate is relative/recursive in CCTS. With Metapattern, a
localized nil identity determines what counts as the object’s relevant context,
and what as its relevant specification. From such a particular localized nil
identity, the context in question may be aggregated as an upward decomposition
and the corresponding specification as a downward decomposition.
Metapattern’s conceptual economy also supports realistic governance of
(contextual) specifications. I’ll treat that vital aspect later, in a separate
section.
Gradual migration
Efforts at standardization are highly political and are influenced by large
commercial enterprises, if not predominantly so. There are now many interests
vested in CCTS and related developments. It is therefore an illusion to expect
that Metapattern is adopted simply because it is structurally superior.
With interests viewed on a longer term, Metapattern should not be ignored. It
does offer advantages when compared to current CCTS and so on.
Because Metapattern operates at a higher level of abstraction and variability,
it provides the opportunity for gradual migration. For example, it is possible
to implement CCTS with Metapattern (but not the other way around). Such an
instantiation would greatly assist analyzing such standards and
recommendations, allowing for experimenting with proposals for further
development. Ultimately, CCTS and Metapattern would converge at a shared
(meta)level.
Part II
(Some) reading comments
The following comments are highly informal. I’ve included them for inviting serious discussion. So, I may be wrong in some or all of my judgments but I’d like to see arguments before I change my mind. I find that’s reasonable.
Please note, below indented texts are reproduced from documentation with their titles appearing here as section headings.
UCM – Requirements List
Context, as a key driver to precisely determine business meaning and intent of information definition and exchange, requires a formal structure and methodology.
Metapattern does not start from some meaning, with context applied
for precision. Context is the only “driver” of meaning.
The “formal structure and methodology” for context is therefore not separate,
but essentially irreducible.
[C]ontext has been identified as a key component of the UN/CEFACT standard[.]
Context, that is, according to Metapattern, is not a component in the sense of a module. Instead, context is all-pervasive and therefore a relative concept. Its relative nature allows for recursive formalization.
With an increasing maturity of a number of standards (CCTS, CCMA, UMM, etc.) that all have strong needs to define and use context, now is the time to form a project to tackle this problem.
A both consistent and efficient context mechanism is an integral part of a
realistic standard for semantic order (necessarily reconciling identity with
differences). While context is treated as a component-as-module, such standards
are simply immature.
I certainly agree with the “strong needs.” The current direction such —
attempts at — standards are taking is counterproductive. Yes, it is vital “to
tackle this problem,” but extending CCTS’s context mechanism as documented in
version 3.0 doesn’t deliver.
So, the idea
to develop a methodology and technical specification for developing, registering, and using context drivers […] start[ing] from the current context mechanism described in the Core Components Technical Specification (CCTS)
will fail if such a start does not involve a departure.
[C]ontext methodology will impact a number of standards artifacts being developed under UN/CEFACT.
It needs to redirect such standards, i.e. change their foundation.
The specification will provide a methodology for assigning context to business information using a number of defined context drivers by advancing the context driver mechanism of the CCTS.
A retreat is in order to advance properly.
What is business, as in business information? The methodology should be as
generally valid as possible. Then, business use is simply some subset of all
usage (with the added advantage that defining ‘business’ become irrelevant).
Even when restricted to business usage (whatever business is taken to mean; already
on the concept of business consensus is surely illusive), context drivers are
impossible to enumerate exhaustively.
A standard should not fixate what in reality is dynamic. Orientation is
methodology is right, as long as it supplies necessary and sufficient
variables.
The difference between variables and their respective domains suggest
differentiation in governance. As it is as general as possible, methodology
correspondingly requires the widest possible governance, whereas a particular
value domain may be determined by fewer (represented) parties.
Any viable standard should recognize that it must also address a realistic
differentiation of governance scopes.
The specification will take into account the ongoing work within TMG (UMM collaboration models), ICG (Registry Implementation Specification) and within TBG (Common Business Process Catalogue).
It sounds politically correct, but “the ongoing work” is heading in the wrong direction. Their results will be irrelevant on any scale that is larger than what is still consistent along hierarchical lines. At the scale of society, and that is what infrastructural standards should aim at, information interactions follow the structure of a network (rather than a hierarchy; please note that already inside a single business or government organization, semantic hierarchy is illusory).
The methodology will also include a recommendation for the code lists that can be used to represent context drivers and a proposal of how to maintain these code lists.
See above for my remarks on the risk of mixing governance scopes. Of course, developing a methodology requires an acute awareness of possible value domains. The responsibility (also read: freedom) to rule some value domain should optimally reside elsewhere.
Review and evaluate current UN/CEFACT standards that are related to and potentially impacted by the context methodology
is the first of “[t]he proposed steps to develop the draft specification.”
I hope to be making a productive contribution to precisely such an evaluation.
The impact of context is foundational.
As the second is mentioned to
[d]evelop a context framework meta-model and a context methodology for the implementation of the meta-model[.]
I suggest that the work group studies Metapattern as a candidate “framework.”
It seems to meet all the requirements, and more. And it doesn’t need to be
developed, as it already exists, including a software implementation for
demonstration purposes.
The third step:
For each area (category) of the context meta-model, develop a taxonomy that can be used to populate the eventual context driver value instance. Existing taxonomies it shall be used[.]
The idea of fixed context categories is already mistaken. Of course, some
elements will materialize requiring a corresponding value domain, or taxonomy.
Yes, it makes great sense to apply an existing taxonomy, at least when it is
accepted/supported. No, again, see above, don’t mix work and thereby
governances.
The sixth step:
Develop first complete draft for review.
As a methodology, Metapattern is immediately available for review.
CCTS – version 3.0
Section 3, Introduction:
This specification describes and specifies a semantic-based approach to the well-understood problem of the lack of information interoperability within and between applications and data bases in the e-business arena.
It may be that “the lack of information interoperability” is by now quite
well-known, but it is still far from “well-understood.”
The assumptions underlying semantics (rather: pragmatics, but here I won’t
pursue the distinction) remain largely implicit. What I can imply seems
ill-equipped for requisite variety at the scale which the standard addresses.
The restriction to “business” is counterproductive. In fact, inviting a more
abstract approach, a general methodology could turn out more compact, etc. as
exemplified by Metapattern.
Traditionally, data has been designed for specific applications and databases without regard to interoperability.
Yet, what particular information means, is exactly what one application
differentiates from another application. Why else would there be … different
applications?!
When identical applications exchange information, there is not a semantic issue
to begin with.
It is only when different applications should coordinate processing,
i.e. interoperate, that explicit semantics become relevant.
Standards for the exchange of that business data between applications and databases have been focused on static message definitions that have not enabled a sufficient degree of interoperability or flexibility.
It escapes me how CCTS adds dynamics. Some mechanism for late binding of message structure?
Th[e] Core Component Technical Specification (CCTS) describes a revolutionary approach for developing a common set of semantic building blocks that represent the general types of business data in use today.
I seem to hold a different view on what productively counts as “semantic
building blocks.” Actually, I would never use the terminology myself.
Then, I fail to recognize what is “revolutionary” about the “approach.” I could
be missing the critical point, though.
Rather than “the general types of business data” it would already make better
sense to argue for the business types of general data. It then becomes easier
to acknowledge that general data are a contradiction, leading to Metapattern’s
concept of the nil identity as the “core component.”
This approach provides for the creation of new business vocabularies as well as restructuring of existing business vocabularies to achieve semantic interoperability of data.
I don’t recognize what is special about CCTS regarding vocabularies (also
read: domain value sets, taxonomies).
Section 3.2:
CCTS […] is especially well suited for defining data models and for creating data exchange standards for information flows amongst and between enterprises, governmental agencies, and/or other organizations in an open, global environment.
I completely agree with the extension of scope for the methodology. As CCTS
stands, though, it is unfit for “an open, global environment.” Upgrading CCTS
requires a sophisticated semantic/pragmatic theory.
Grounding Metapattern, I’ve developed subjective situationism as such a theory.
A particular application may (also) be considered a subject, behaving
differentially according to a pertaining situation. With situation
corresponding to context, requisite variety is promoted.
Section 4.1:
The CCTS has been developed to provide for standards based semantic data modelling.
What does that sentence mean? My guess is that … in this context …
“standards” refer to the core components according to CCTS (which are not core
components as I would argue for). Such core components are supposedly
context-independent. Please note that core components as in CCTS are configured
into a full-fledged model. It is the core model from which, through some
context, a particular business model may derived (as a refinement). Then, the
business model in question is seen as equipped with semantics, i.e.
sufficiently precise meaning for some business objective.
So idea seem to be, let CCTS do the core modeling. Then you can concentrate on
your relevant business model. Deriving your model from ours is the application
of semantics.
Of course my interpretation may be way off …
Applications will be considered to be in full conformance with this technical specification if they comply with the content of normative sections, rules and definitions.
Sounds strict. However, is there a range, or space, for compliance?
I find it impossible to imagine that some application provider will invest in
achieving compliance. That may be just as well, since the “technical
specification” is not really leading to a solution (except, possibly, in the
short term for the it supplier advancing its own limited set-up as the standard;
or am I being overly cynical?).
Section 5, Overview:
Th[e] Core Components Technical Specification (CCTS) provides a way to identify, capture and maximize the re-use of business information to support and enhance information inter-operability across multiple business situations.
What does “situations” mean there? Is it synonymous with application,
thereby arguing that “multiple business” applications can interoperate?
Or does it mean processes? Does CCTS support applications to use information on
the basis of different business-specific models, one of them which is relevant
for a particular information/service exchange?
I don’t think the claim that CCTS “maximize[s …] re-use” will hold up. In a
networked world, the essentially hierarchical framework consisting of core
model, business process model and application model in fact maintains
redundancy.
Or, what am I missing …?
The CCTS approach is more flexible than current data and information exchange standards because the semantic standardization is done in a syntax-neutral fashion.
What does it mean, “in a syntax-neutral fashion”? Such neutrality is
impossible. There’s no escaping syntax in information.
It might mean that CCTS aims at metainformation. As such, it attempts to
abstract from specific applications as much as possible.
This syntax-neutral semantic based methodology allows for the richness inherent in natural language to be used to create data and information exchange models that are devoid of computer-driven syntax limitations and requirements.
In section 4, it reads “standards based semantic data modelling.” Now it
says that the methodology is “semantic based.” It might all make perfect sense,
but speaking for myself it takes much effort from the reader.
Positioning CCTS as capturing “the richness inherent in natural language” is
clearly nonsense.
Why the rhetoric of inflated claims? There is nothing wrong with aiming at
precision for exchanging information/services. And for that purpose, CCTS
misses productive assumptions, that is, a semantic/pragmatic theory wit
requisite variety.
UN/CEFACT business process and core component solutions capture a wealth of information about the business reasons for variation in data model and message semantics and structure.
Different business-specific models are supported, yes (but without
redundancy control). Linking one such business-specific model to the core model
is some business context, yes.
When it is argued that such a context “capture[s] a wealth of information about
the business reasons for variation,” the current context mechanism is still
inadequate.
In the past, such variations have introduced incompatibilities. The core components mechanism uses this rich information to allow identification of exact similarities and differences between semantic models.
Indeed, without contextual differentiation “incompatibilities” are
impossible to resolve into the realistic differences they should be recognized
as.
Not “rich information,” but a unique contextual identifier is required to
unambiguously relate a particular semantic model — at least I understand it
here as synonymous with a business-specific model — to the core model.
Core components are the linchpin for creating interoperable business process models and business documents.
My understanding of CCTS is that the configured core components exhibit a
core model. And from that core model may business-specific models be derived.
Or am I really not getting it at all? Is there, indeed, a core model. But is
context applied to its elements separately (as figure 5-2, further on, might
suggest), allowing for greater refinements? If so, is it possible to apply
context a to core component x, while applying context b to core component y?
But then, how are such derivations as business information entities combined into
a business-specific model … on the basis of context? If so, which context?
It makes me wonder whether there exists an implementation of CCTS. Does it
really work? How, exactly? Or, when it does work, why not?
There are
three different categories of core components – aggregate, basic, and association[.]
I would treat basic as a boundary case of aggregate, leaving only two
“different categories of core components.”
And I would radically change the concept of core component, as already
repeatedly explained.
Section 5.1.1 introduces
[a]n Aggregate Core component (ACC) [a]s a collection of related pieces of information that together convey a distinct meaning, independent of any specific context.
However, on the basis of explicit associations it is not “a collection,” but
instead refers to it.
Likewise, in section 5.1.2 the formulation is somewhat loose:
An Association Core Component (ASCC) is a complex property of an ACC that associates two ACCs, where one ACC is a property of the other.
Again, the explicit association is not a complex property, but
‘simply’ refers to another aggregate core component.
I am especially taxed by a statement such as:
The ASCC Property is reusable across object classes, but once it has been given the object class of a parent ACC, it becomes an ASCC that is unique to the object class to which it is assigned.
Does it mean that, in this case, indeed an association starts out as a
separate building block? Is it as such, then, potentially “reusable across
object classes” (read: already configured aggregate core components). But as
soon as the association in question is included in the core model as
configuration, it adapts to its “unique” position as reflected by its new,
extended name.
When more, all uniquely positioned associations are, say, specializations from
the same building block as generalization, are they still somehow related in
the core model?
Are aggregate core components reusable in that sense? I didn’t come across a
statement such as: The ACC Property is reusable across object classes, but once
it has been given the object class of a parent ASCC, it becomes an ACC that is
unique to the object class to which it is assigned.
However, in section 5.1.3 it reads:
The BCC Property is reusable across object classes, but once it has been given the object class of a parent ACC, it becomes a BCC that is unique to the object class to which it is assigned.
Some of my comments on the association apply equally to the basic core
component.
In this case, though, I don’t take offence at “property,” as CCTS doesn’t place
an explicit association between an aggregate and such a basic
attribute/property. I would have …
Section 5.3:
Core Components act as conceptual models that are used to define Business Information Entities (BIEs).
Is a separate core component a reference model for an equally separate
business information entity? Then, how are those derived entities configured?
Implicitly, as the core model dictates?
My impression is that business information entities are just as conceptual as
core components. Core components serve as a reference, which is something
different.
BIEs are created through the application of context and may be qualified to guarantee unique business semantics.
A specific relationship exists between CCs and BIEs; BIEs are always derived from their source CC.
There it is! A single BIE has a single CC as its “source.”
Thus, the structure of CCs and BIEs are complementary in many respects.
But then, what holds some BIEs together as a particular structure when
several business-specific structures may be derived from the CCs?
Do I still miss a vital point? Or am I asking questions for which CCTS is not
yet equipped and UCM is now called upon to provide answers to?
Business context is a mechanism for qualifying and refining CCs according to their use under particular data model or business information exchange circumstances.
Are “business information exchange circumstances” different from “business
context”? If so, how are they related?
Could it be that CCTS, version 3.0, stopped at “business context” as the
proposed mechanism for deriving a single BIE from a single CC? Is Metapattern
really that far ahead?
In CCTS, business context is formally described for specific business circumstances for each BIE.
But where is the connection?!?
A note at the start of section 9, Context, announces:
The context mechanism is being more robustly defined in a separate UN/CEFACT Context Methodology specification. Once the final version of that specification is published, This section will be deprecated.
UMC will first of all need to clarify CCTS’s concept of context. I could be
that I am overlooking essential structural guidelines. Even when I do, and CCTS
is actually perfectly consistent, complete etc., I would find it impossible to
apply on the basis of my current understanding.
Or doesn’t CCTS supply “[t]he context mechanism” which only requires “being
more robustly defined in a separate UN/CEFACT Context Methodology
specification.”? Without a robust foundation, it can never be made to work.
To me, such a foundation is either unclear, or I find it lacking.
Whenever business collaboration takes place between specific trading partners, data is exchanged in the form of business messages. When used as such, that data exists in a particular business context.
I’m still baffled, again by such a sentence from section 9.1. I find it
clear that “data” as in a “message” is plural. It is also explicitly stated
“that data exists in a particular context.” Repeat, “particular,” which is
clearly refers to a singular context.
Is “context” used with two different meanings? Then, does “in a particular
business context” equate with “business information exchange circumstances”?
And does it not coincide with context as in the derivation/refinement mechanism
between one BIE and its single source CC?
But then it says referring to “in a particular business context” that
[i]n its simplest form, this is the idea of context as used in this specification.
With context in that “simplest form,” a message would contain a single data
item, only.
A specification is only robust when supporting context at its most complex, as
long as it remains relevant. Again, it is all about requisite variety. Seeing
merely “its simplest form” referred to reinforces my evaluation that CCTS needs
a radical departure for contextual differentiation.
The context in which the business collaboration takes place can be specified by a set of categories and their associated values.
It should be evident that “the business collaboration” is a wider context than
what might relate a single BIE to its source CC.
Metapattern is based on different assumptions altogether.
Part III
Starting from zero!
I’ve been reading and rereading relevant parts, yet a thoroughly systemic analysis of CCTS eludes me. I find several of its structural concepts confusing. It may be that I just don’t have the required background for a proper understanding. Meanwhile, I’ll try to restate CCTS’s foundation in a way that makes more sense to me.
The way CCTS applies the concept of core component already involves
contextualization. I would say that a core component should really be a
separate building block.
Then, what (still) are called core components in CCTS, actually are
differentiations while configuring those into, say, a reference model. Figure 1
is my sketch, with my idea of core component included. By the way, I’ve also
made an association explicit for a simple attribute.
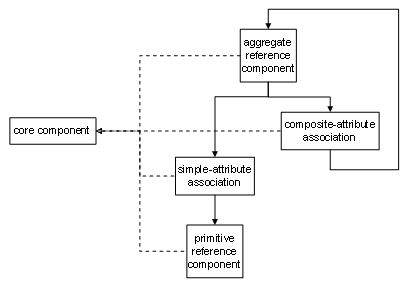
Figure 1.
Contextualization into a particular reference configuration follows, I would say, from directions such as “[...] is reusable across object classes, but once it has been given the object class of a parent […], it becomes […] unique to the object class to which it is assigned.” However, I don’t recognize actual reuse in CCTS. For such a component does not remain available separately, i.e. as a genuine core component. As I read CCTS, “core” always implies a unique structural position.
From structurally positioned core components, as in CCTS, I believe it follows that the step from core components to business information entities involves some (sub)structure as a whole. With figure 2 I’ve attempted to illustrate the realistic scope of deriving one or more business-specific models from a (general) reference model.
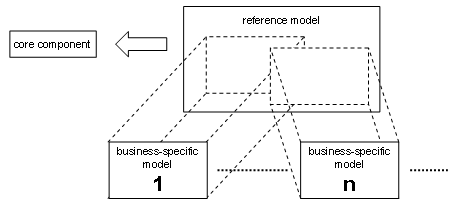
Figure 2.
What CCTS considers contextualization is only the derivation of a particular business-specific model from the reference model. Please note, it requires the reference model to be free from inconsistency both structurally and in terms of value domains. For as it is assumed to be context-independent, there is no mechanism to accommodate relevant differences at that reference level.
Context-independent equates with contradiction-free. As a requirement that is unrealistic. This assumption undermines CCTS. It also means that whatever governance can never resolve essential differences.
Still, there is another differentiation step, i.e. an additional contextualization, that I fail to recognize explicitly in CCTS. It resides in the particular application of a particular business-specific model by several actors, including so-called … applications; see figure 3.
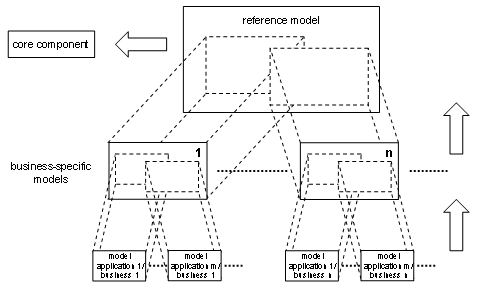
Figure 3.
Separate applications (also read: services) cannot be counted upon to behave in a consistently subordinated fashion re. a particular business-specific model. For competitive advantage often lies precisely in breaking such an established hierarchy.
Metapattern removes such fundamental obstacles. It is beyond the scope of these comments to explain Metapattern’s assumptions; see elsewhere for relevant documentation.
Here, let me just state the flavour. Metapattern does not confuse core with structurally positioned, albeit at the reference level. As a core, an object (or component) is explicitly devoid of attributes. It entails a so-called nil identity, nothing else. Even as a nil identity, for the sake of uniform treatment, it is fitted with a context, too. That is the nil context. So, nothing is context-independent!
The whole idea of an intermediate reference model is discarded. But then business is far too coarse (and far too simplistic) a concept for relevant contextualization. Metapattern lets any contextualized object serve … as a further context. Such recursiveness promotes conceptual economy.
Reuse is maximized because such contextual flexibility supports disjunct specifications between any contexts.
In its current version (3.0), CCTS lacks both consistency and economy (efficiency). Developing UCM offers the opportunity to correct for CCTS both its essential inconsistency (which is, paradoxically speaking, that it doesn’t support … inconsistencies) and redundancy (because its claims for reuse are ill-founded).
As I see it, UCM should not be an improvement upon CCTS’s current context mechanism. Instead, CCTS should be improved as a whole. With Metapattern, what serves as a core component should be essentially shifted. Such a move may be compared to including zero as a number. Treating nothing as something, too, may at first seem counterintuitive but precisely that assumption provides for a consistent system.
notes
1. I am grateful to Jan van Til for bringing, early September
2007, UCM to my attention.
2. I’ve published extensively on Metapattern. My publications are listed, on
for the most part available, too, on my website (www.informationdynamics.nl/pwisse).
My earliest text (1991) is in Dutch, an essay translated later into English as Multicontextual
paradigm for object orientation: a development of information modeling toward
fifth behavioral form. My book Metapattern: context
and time in information models (Addison-Wesley) appeared in 2001.
3. http://www.unstandards.org:8080/display/public/UCM+-+Requirements+List+.
Website consulted on September 11th, 2007.
4. http://www.unece.org/cefact/.
Navigate to “about us,” then “introduction.” Also directly available at http://www.unece.org/cefact/about.htm.
Website consulted on September 11th, 2007.
5. Ibid.
6. Ibid.
7. http://www.untmg.org/.
8. Ibid. Navigate to “Core Components WG.” Also directly available at http://www.untmg.org/index.php?option=com_content&task=view&id=25&Itemid=55.
Website consulted on September 11th, 2007.
9. http://www.untmg.org/. Navigate to
“Business Process WG.” Also directly available at http://www.untmg.org/index.php?option=com_content&task=view&id=15&Itemid=58.
Website consulted on September 11th, 2007.
10. http://www.untmg.org/. Navigate to
“Core Components WG.” Also directly available at http://www.untmg.org/index.php?option=com_content&task=view&id=25&Itemid=55.
Website consulted on September 11th, 2007.
11. Ibid.
12. Details on CCTS are taken from UN/CEFACT Core Components Technical
Specification, Version 3.0 (http://www.unstandards.org:8080/download/attachments/3801818/Specification_CCTS3p0+2nd+Public+Review+16APR2007.pdf?version=1).
13. For a comparison of Metapattern to Buchler’s metaphysics, see Metapattern of natural
complexes: enlisting Justus Buchler’s metaphysics for informational
infrastructure (in: PrimaVera, Amsterdam University, 2006).
14. Part I of Metapattern: context and time in
information models (Addison-Wesley, 2001) outlines the formal model
including nil identity. It is reproduced in The pattern of
metapattern (in: PrimaVera, Amsterdam University, 2004). I’ve explained
identity’s “radical minimalism” more recently in Ontology for
interdependency: steps to an ecology for information management (in:
PrimaVera, Amsterdam University, 2007).
15. Please consult the references.
September 2007, web edition 2007 © Pieter Wisse