Multicontextual paradigm for object orientation
a development of information modeling towards fifth behavioral form
Pieter Wisse
1. Introduction
The paradigm of object orientation is rapidly growing in popularity. Professionals work at design, development and maintenance of information systems based on object technology. Many information scientists contribute through their research. For the most part, the results of both practice and theory have been positive. With object orientation, opportunities exist to improve the quality of information systems and services to support complex organizations and organizational processes.
Does object orientation or OO, for short, have no drawbacks at all? Well, misleading, to say the least, is the uninformed hype promoting this latest movement in information technology. It constitutes a real danger that OO will not develop beyond a superficial fashion.
In order to remove obstacles for the deployment of object orientation, it is vital to be realistic and to suppress exaggerated expectations. So, what are real problems with object orientation? Do solutions exist, both theoretically and in practice?
Indeed, on the basis of growing experience with information systems & services, current object orientation shows several serious shortcomings. A fundamental defect makes an object always a member of just one class, that is, in terms of definition of the object's behavior. This severely limits applicability of OO for complex organizations and organizational processes.
I have chosen an opposite starting point. It has led to a broader, multicontextual paradigm to replace the current paradigm for object orientation. My extended version assumes the basic reality of behavioral diversity of one and the same object. Manageable solutions for complex information problems result from a reorientation based on this concept of diverse behavior.
In what follows, I develop a series of formal definitions of information that is to be modeled as multicontextual objects. My final definition to date is called fifth behavioral form, by informal analogy with relational data base theory. Information as objects in fifth behavioral form constitutes a necessary and sufficient condition for comprehensive encapsulation. That what is encapsulated is, first of all, everything that I refer to as the intext of the object. Secondly, an object in fifth behavioral form contains all of its separate contexts. Put into practice, the multicontextual paradigm leads to increased flexibility to suit a wide variety of informational situations. That way, a real problem has turned into a real opportunity.
2. Diversity of behavior
Behavior is often surprising. For instance, observe the behavioral acts of a person whom you consider a friend. Suppose you have come to know him (or her, of course) as an extraverted entertainer. To every question, he replies with a humorous answer. It will be surprising, indeed, to experience him for once being modest and silent, even very shy. For example, take two questions put into exactly the same words. It could happen that only a few moments ago he would have answered with a joke and now, where the situation has changed, his insecurity is overt.
If he really is your friend and, therefore, you continue to be interested, you will also try to understand his sudden shyness. There is only one valid course to take and that is looking at — your interpretation of — his diverse behavior. Perhaps the explanation is that he is always extraverted when he feels at home but is reserved with strangers. Anyway, your interpretation will never go so far as to suppose that it is not one and the same person you are experiencing. You will never conclude that your idea of him as one single, whole person is an illusion and that in reality there are two persons. You will rightfully assume that both the extraverted and the introverted behavior remain integrated in the same person with his overall identity.
3. Objects and epistemology
In the course of applying object-oriented information technology, an obvious design choice is to designate that single person or, in other words, that human being as an object. However, this does not immediately imply that such an object, having a unique identity, should exist in an absolute, external reality. Still, many designers, in a philosophical sense being naive realists, assume an absolute reality that can be mapped onto knowledge on a one-to-one basis. In their view, information (a signifier) stands for something real (the signified). The object in the real world is accorded absolute existence.
But I do not even have to refer to the extensive literature on psychology and phenomenological philosophy to establish such an epistemological idea as being too simple and thus outdated. However, most designers and developers of information systems are still philosophically and psychologically illiterate, which is why they consider information as the immediate representation of something belonging to the external reality, i.e. of an object with its own absolute existence. And information scientists, I am afraid, do not seem that much better informed than professionals.
I support a point of view that is philosophically more sophisticated. Its axiom is that knowledge and subject are structurally tightly-connected concepts. Therefore, the cognitive faculties of the designer are also a decisive factor. In other words, the choice of objects is always to a large extent subjectively determined. Instead of concentrating on external reality, whose existence is beyond final proof anyway, every designer should follow the epistemological route, i.e., he should concentrate on his own cognitive faculties. A corollary, of course, is that designs can fundamentally differ as one designer's cognitive faculties are often completely different from another's and also work in a completely different way. Therefore, it is even logical that resulting designs can vary enormously. I developed this idea of subjectivism in design more comprehensively in an earlier article 'The Quality of Object Orientation is Subjective' (title translated from the Dutch).
For the current exposition, I conclude this axiomatic discussion by repeating that the multicontextual paradigm is all about objects and their identity in the cognitive model of a designer. The external reality is too far removed to serve as the basis for breakthroughs in design. It is sufficient to deal with objects and their identities in cognitive models. This leads to the comfortable position that formal propositions about the 'reality' of reality can be avoided.
At this stage, I also wish to clarify my use of the words design and designer. From a phenomenological point of view, as introduced above, information modeling always involves creativity on the part of the subject doing the modeling. It is not mere analysis, i.e., a passive recording of a real world that has absolute existence. The resulting model is not independent from the person doing the modeling, that is, of what in almost all Anglo-Saxon literature on information systems is referred to as the analyst. Therefore, against all current convention, I favour design before analysis to indicate this often highly creative activity of modeling. More on exchanging the concept of analysis for that of design is included in my article entitled 'Aspects of Object Technology' (title translated from the Dutch).
4. Cognitive models and the current OO paradigm
As the example of the person who behaves both extravertedly and introvertedly but in different situations shows, one and the same object can exhibit extremely different reactions to what is in itself essentially the same message. In my example I assumed a person being asked a question. Imagine how many different reactions may be evoked by the question "Do you love me?"
As shown by the previous paragraph, the relationship between (cognitive) models and reality is problematic. Every model is artificial because of its subjective content. However, some models are more effective than others. The measure of effectiveness is derived from how effective model-based behavior is. For all behavior is based on models.
Using the current OO paradigm, cognitive models will often be ineffective in view of the diversity of behavior that must be attributed to, or is required of, one and the same object. A number of modeling alternatives will make this clear. The first alternative below in particular falls far short on pragmatics and therefore flexibility for complex information systems and services. And even the third modeling alternative based on the current OO paradigm has severe limitations. These problems are caused, in my opinion, by the simplistic axioms underlying the current paradigm or, to be more specific, the assumption that - specific behavior of - an object is always determined by one, and only one, class. That there should be a minimum of one class is evident. The freedom to establish more classes follows the move from a paradigm based on a single context to a multicontextual paradigm for object orientation.
Before introducing the extended, multicontextual OO paradigm in the second part of this paper, I will sketch several modeling alternatives for behavioral diversity using the current paradigm. I follow this approach because a solution often becomes self-evident as soon as the problem has been explored in depth.
In order to appreciate my exposition, the reader should be fairly familiar with the basics of object-oriented information technology as it is practiced and theorized about today. Readers who need to catch up will find titles of several introductions to the subject at the end of this paper.
As representative of the current OO paradigm and as reference point for my modeling alternatives, I have taken Object-Oriented Analysis by Coad and Yourdon. My main reason is that this book has been widely distributed. It should therefore be possible to follow-up on my concrete references without too much trouble. And for my objective here, it is relevant that their position on object orientation is often too simple. Major problems are left untouched. It is this contrast that serves to introduce my extended paradigm. At the same time, and quite to the contrary of the hype they do not hesitate to include, Coad and Yourdon exhibit a pleasant modesty. For instance, I like their observation that (p 7) object orientation "will continue to evolve." It comes as a relief that they, after all, do not pretend to offer the final word on object orientation.
I want to communicate an even more radical openness to new ideas. There is always room for development, a need for improvement. Important as I believe it to be, I consider the multicontextual OO paradigm as a next step, not as the ultimate theory. There is no such thing as an ultimate theory (as the paragraph on objects and epistemology has made clear).
5. First model based on current OO paradigm: behavior of roles
The first modeling alternative, including my criticism thereof, starts with the designer departing from the notion of a single person who is the integrated carrier of diverse behavior. Of course, there is a class for person objects, but this class remains empty. So, strange as it may seem, the person class does not contain any person object. This alone, already yields superclass status to person class.
Actually, in my illustrations, I use different symbols for class and object than Coad and Yourdon. The reasons for digression are explained as my exposition proceeds.
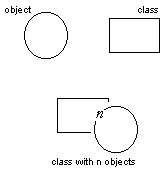
illustration 1
Given my basic example of diverse behavior, what does the first alternative for information modeling look like? As I already mentioned, there is an empty superclass for persons. Next, for the attributes of extravert and introvert the designer creates two corresponding subclasses. Extravert and introvert take the shape of different behavioral roles that the same person can play at different times in different situations. Both subclasses will contain objects as the person behaves accordingly.
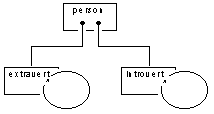
illustration 2
What is wrong with this model of information? A problem occurs when behavioral roles are not disjunct. One and the same person is neither completely extraverted nor completely introverted. Of course, he will most probably not behave extravertedly and introvertedly at the same time, but for this discussion the conjunctness of behavior pertains to the individual human being and not necessarily abstracts from the dimension of time. The behavioral diversity manifests itself through one and the same person. Herein lies the challenge for the designer.
Coad and Yourdon write extensively about the relationship between object classes based on the principle of generalization versus specialization. The idea behind this classification is to define at the top of a hierarchy, let's say, the commonest denominator of behavior. A class types, i.e. is the type for, the behavior of the objects belonging to it. In addition, the given rules control the behavior of objects in all lower classes, that is, as long as no overriding rules have been stipulated at a lower level in the class hierarchy.
First of all, I point out that class as a typing concept does not cover another meaning of class. The other concept establishes class as a set. In that case the objects are its elements.
Designers are often not aware (enough) of the two meanings of class, i.e., as a type and as a set. This results in confusion, bad design, and so on to information systems that do not function properly. Coad and Yourdon and many others fail to warn against such confusion. It is only in more scientific literature that attention is paid to (the difference between) class-as-type and class-as-set. It is a painful omission in popular text books. Practitioners are not given necessary guidelines and the quality of design and resulting information systems suffers.
The classification domain of generalization versus specialization is limited to typing (the behavior of) objects. Based on typing, of course, it is possible to construct an information model that is, say, internally consistent. The price to pay for such specialization, however, is that the design approach leads straight back to square one in terms of conjuct behavior or, to be more precise, of conjunct objects for diverse behavior as exhibited by an integrated 'personality.'
Let the designer start with person as the most general class. As a matter of principle for Coad and Yourdon, its specializations are not alowed to overlap. Now, as a safeguard against conjunction, a third subclass must be introduced for those persons who could be both extraverted and introverted. But then, this additional subclass corresponds exactly to the original generalization. Without the subclass in whose objects extraverted and introverted behavior can be united, the other two subclasses (as sets) could overlap as far as the unique integrity of the objects is concerned. As it is, the superclass was already empty. Now also both original subclasses must be empty where conjunctive behavior is realistic. Only the additional subclass contains objects. So what has been gained by specialization? On the contrary, efficiency has been lost as there will undoubtedly be duplication of (definitions for) variables and/or methods. And as for behavior, not a person object must be addressed but the subclassed role that integrates extraverted and introverted behavior.
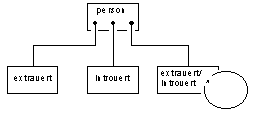
illustration 3
The model structure that Coad and Yourdon explain using the generalization/specialization classification is convincing, but only at first sight and in theory. Upon inspection, there are major difficulties present that make the current OO paradigm deficient for practical information services in any but the most simple situations. By now the argument in support of my criticism should be clear. The condition of concurrence of disjunct identities and disjunct objects often does not hold.
As I mentioned, one of two relevant meanings of the class concept deals with typing individual objects. That is, objects of the same type exhibit similar behavior, at least their behavior is based on the same variables and methods (operations). Being of the same class-as-type, objects can share definitions of variables and methods.
To design an information model on the basis of a class as a type remains valid for as long as relevant attributes and roles are disjunct and recognizable through their own, unique identities. Only then, is the conclusion justified that (C&Y, p 81) "[e]ach specialization is named in such a way that it can stand on its own." I feel this citation to be an excellent summary of the falsehood of many assumptions as they are applied to complex information systems. For, on the contrary, a specialization often does nòt stand on its own at all, but is only valid in a certain context. Only then and there, it types the specialized behavior of the broader object. Further on I will take up the point of whether the class of the broader object could be subject to generalization. Here it is sufficient to declare that specialized behavior in a certain role is often disjunct from behavior that typifies the object-as-a-whole.
Another criticism of the design practice related to (disjunct) specializations as suggested by Coad and Yourdon connects to their prescription that every specialization should stand completely on its own (and, therefore, belongs to one class, and one class only). Take their example as presented on page 88 of Object-Oriented Analysis. A <ClerkPerson> can, at the same time, be the owner of a transport vehicle. Therefore, at a next lower level of hierarchy, a (sub)class is added to accomodate this conjunction. I see this as the solution for a problem that should not occur in the first place. For how is the overall identity guaranteed of the person concerned? How is it known that a person is both owner and clerk? The model based on generalization and specialization does not provide a consistent structure, with overall identities in the right place(s). Again, it is revealing to look beyond the written text by Coad and Yourdon for possible practical reasons. The generalization/specialization classification and its resulting models and structures seem only to serve minimal typing definitions. Even when roles are strictly disjunct, a problem with specialization according to Coad and Yourdon remains that every specialized object "stand[s] on its own." To induce the behavior that is specifically required, or even necessary, an object different from the object-as-whole must be invoked. The person superclass is, as I have shown before, an empty class. Following their guidelines, the complete set of all persons must be emptied into the sets that reflect the specializations as defined by the (three) subclasses. This, however, is too far removed from reality - or should I say, from a realistic model of reality? In short, too artificial and ineffective. A consistent model as seen from the outside starts and ends with the integrated person as the recognizable, invokable etc. object. All person objects should be part of the same set, irrespective of typing of their behavior into different roles. The next step is to view the role of, for example, extravert as part of the whole, integrated identity of a person. An information model comes out completely wrong if, on the contrary, a role is typed as a subclass of person and, therefore, still as a person but only with somewhat specialized behavior. For owners, clerks and for those who are both owner and clerk at the same time, the guidelines of Coad and Yourdon lead equally astray. With three subclasses (as types), inheritance may seem at an optimum but the resulting separate sets cause problems in other areas. Considering all aspects of information systems, promoting roles to objects of a subtype will often be harmful.
Here, the direction for an overall solution, even while still using the current OO paradigm, already becoms clear. My own first guideline is nòt to leave the superclass empty. See below for the third modeling alternative. And as that model is still wanting, a consecutive paradigm shift is unavoidable. The extended, multicontextual OO paradigm is introduced in the second part of this paper.
6. Second model based on current OO paradigm: procedural programming
Another design solution is to limit the class (a set) and its objects (the elements) strictly to persons. It is interesting, by the way, that Coad and Yourdon do not at all mention this alternative. Is it too traditional? Maybe they were no longer aware of its possibility, much as they must have been charmed by their new-found productivity tool for typing inheritance. Or, maybe, this alternative does indeed look too traditional and was, therefore, left out because it is not suited to promote object orientation as a completely novel approach. Well, for the record, I do not believe that object orientation is all that revolutionary. It is much better understood as a development stage in an evolutionary process, one shackle in a whole chain of information technologies. As such, it can certainly improve upon earlier technologies but, at the same time, introduces its own draw-backs. That is all very normal from an evolutionay perspective.
Let me continue with my second alternative to model the relevant information. Limiting all persons to a single class reflects, of course, their integrity and unique identities. So this seems, right away, a far healthier starting point for design. But now a problem shows up elsewhere. What I considered earlier to be equal messages are no longer sufficient. The message to invoke a behavioral act has to be enlarged. An operand has to specify the relevant situation or context. Returning to my example, the choice is between an environment/situation that is either familiar or strange to the person in question.
The object invoked should react by exhibiting adequate behavior. In terms of a computer program, this amounts to conditional processing. The process is embodied in a method, taken from the object's store of methods. Maintaining the object's integrity, however, such as representing a whole person, may lead to a large, heterogeneous method. The consistency of specialized behavior requires that one method retains control over the behavioral process. This includes that situational conditions are tested, every time instructions are executed that represent the specialized behavior.
How the method is constructed internally is beyond the scope of my second modeling alternative. It should be sufficient to refer to professional practices for structured programming and related techniques (about which, by the way, especially Yourdon should be able to explain a lot).
question
do you love me?
answer
if the situation is familiar
then exhibit extravert behavior
if the situation is
strange
then exhibit introvert behavior
extravert
..............................
..................
.........................
introvert
..............
..............................
........
illustration 4
A complicating factor, often, is that the complete set of relevant situations is unknown. New situations may arise, others become obsolete. This makes the comprehensive behavioral method not only extremely heterogeneous, but also volatile. None of this really supports ease of development and maintenance of such methods.
Then, as I already suggested, the second modeling alternative can not hide that such application of object orientation actually forces the designer and developer back to the procedural primacy of an earlier information technology. Those were the days when structured programming matured. Object orientation should not be a redefinition, but now wrapped in the latest fashion paper, of something that is already widespread. It should add something, not withstanding the fact that earlier techniques should always be assimilated within the new paradigm where there is a clear need for them. Structured programming, for example, is such a technique that should be part of every information technology where (digital) programming of any complexity is required.
7. Justification of choice
A designer who wants to prove faithful, if not to the content, to the form of object orientation will usually opt for a division into subclasses. In case of conjunctive roles, he will violate the integrity principle. See above, where I explained the first modeling alternative.
As far as OO goes, that still seems the least damaging design alternative. But actually, there does not have to be anything wrong with following a more procedural path to — programming of — information processing. The difference between both alternatives is only relative, never absolute. In practice, even in the most finely grained behavior specialization through classes, some remnants of procedural processing will always remain.
More classes, obviously, lead to a greater number of methods (procedures). But with many classes, of course, every method by itself will likely be smaller than methods for just a few classes. This is a straightforward relationship as the variety of the organizational problems to be addressed with information systems remains the same of, anyway, does not decrease.
Here I coin a term to use classes as a mechanism to evoke specialized behavior: predifferentiation. Another mechanism to the same effect is called postdifferentiation. The difference between both mechanisms resides in the moment the actual method is activated. With predifferentiation, as the term is supposed to suggest, classes are used as a primary means to separate behavioral acts: a class represents a (smaller) subsets of behavior. With postdifferentiation, the class does not act (so much) as a subset of behavior: activating one behavioral act over others is left to the method. Or, expressing it in jargon, postdifferentiation controls disjunct behavior of a conjunct object all inside a single method. I mention that both these mechanisms are closely related to pre- and postcoordination as practiced for information retrieval and with a longstanding tradition in the field of documentary information services.
Martin, who is actually sort of an institution for practitioners in the field of information systems, strangely does not seem to understand (p 42) the significance of what I put forward as pre- and postdifferentiation. He reports without reservations that complexity of software modules decreases dramatically through object orientation. In my opinion, this is, also dramatically, dependent on the choice of objects and their classes. As I have tried to show before, such design is not simply a matter of optimizing along a single dimension. For a real comparison between information technologies and inherent complexities, pre- and postdifferentiation, for example, need to be examined in the context of their mutual dependence. Martin only looks at postdifferentiation within the objects/modules but apparently forgets that the predifferentiation into those objects/modules also adds to complexity. I agree that the total complexity of a well-designed model can decrease through object orientation as it offers more and especially more transparant opportunities for predifferentiation than earlier information technologies. But the reasoning to such a conclusion should be sound, the more so as bad design will surely lead to more complexity in systems whatever the information technology. Uncritical remarks such as Martin's, place object orientation in too favorable a light. I repeat that the danger is that early conversion to OO and, after disappointment, early rejection are not properly justified. That is dangerous about all hype and fashion. What starts as a self-fulfilling prophesy ends up self-defeatingly. I propose to understand object orientation, with all the relevant opportunities and draw-backs, to make a sound judgement possible about its applicability. Then it becomes clear that object orientation is more suited for some applications than it is for others. It is not a matter of all or nothing. Object orientation, again, represents a stage in evolving information technologies. Ongoing reseach and experience are necessary to apply it to maximum effect and, also, lay the ground for next developments.
8. Third model based on current OO paradigm: roles and parts
A third alternative to modeling still comes within the reach of the current paradigm for object orientation. It appears that the absolute choice between, on the one hand, more classes and, on the other, methods on a traditional procedural basis is not inevitable. Even the current paradigm allows an intermediary model. Again, as with the second alternative, I start by recognizing the possibility of behavioral diversity of one and the same object. Or, in other, more elevated words, the potentiality of behavior changes from uniform to pluriform, from single to multiple.
So far, this is exactly like the second modeling alternative presented before. Plurality corresponds to the divergent situations the object can find itself involved in and where it can be confronted with messages that are otherwise completely equal. For example, look again at the question "Do you love me?" being put to the same person but in different situations.
The departure from the second alternative is as follows. According to the third information model, not just one procedural information process (also read: method) has to deal with the situational diversity through testing conditions. It follows that the different situations, as they are relevant for an object's different behavioral acts, will be translated into different objects. This seems to point toward the first alternative with its subclasses specialized from the person superclass.
The fundamental difference here, however, is that no separate objects are designed, that is, no completely independent objects that stand on their own. The subdivision takes place wthin the original object. The parts in the sense of roles are not separate but remain integrated inside the object-as-a-whole. As such, they function at the same time as the integrating parts of the whole. This information model respects the insoluble integrity of the original object and its identity.
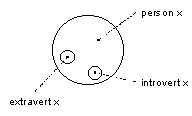
illustration 5
illustration 6
The two illustrations 5 and 6 are equivalent. The symbol convention of illustration 6 provides more space for recurrence because the part is not drawn within the confines of the encapsulating whole. This notation serves a purpose with extensive hierarchies where parts can, in their turn, be wholes to parts at the next level of elaboration. See illustration 11 for an example of such a recurrence of the whole/part relationship. Many details would make a (representation of a) model incomprehensible but, of course, the basically hierarchical nature of the information is more clearly visible through illustrations such as 5 and 11.
The most fundamental difference between the first and third modeling alternative is that objects representing roles such as extravert or intravert are not modeled as specializations, but as parts of an overall person-as-object. Of course, apart from divisions according to generalization/specialization, Coad and Yourdon amply treat the whole/part division between objects (in their book, see from p 90 on). What they do not make explicit, regretfully, is that objects, representing conjunct roles of an overall object, should be modeled as its parts instead of as specializations of the class of the object-as-a-whole.
The consequences of modeling extravert and introvert as parts of a person instead of as specializations of a person class are evident. First of all, there is no more empty superclass called person. It is, on the contrary, filled with àll the objects representing persons. The objects for the roles, extravert and introvert respectively, are parts of the object for the person-as-a-whole. This means that every person can be a set of its own, with other objects as elements. But it always remains to be seen whether, for example, extravert is a specialization of person as generalization. The answer will more often be negative than positive. Only when, in this case, the extravert class (type) shares sufficient variables and methods with the person class (type) is a model on the basis of generalization versus specialization effective. And in case of single inheritance, there is always the question whether the person class is the most efficient generalization of the specific role as a class. It seems more probable that behavior could be shared with objects from another class. That class, or a mutual superclass, is then the most suitable candidate to be superimposed in the hierarchical line of behavior typing.
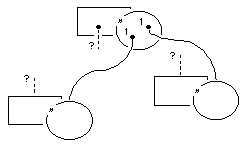
illustration 7
Imposing my concrete example upon the abstraction of illustration 7, it shows a single person has one, and only one, part that represents his extraverted or his introverted behavior, respectively (for such is the assumption for my example on diversity). The number of parts is indicated by the number shown inside the object that acts as the whole.
The same illustration shows another vital distinction. One aspect of cardinality deals with the number of parts of a certain type that a whole may, has to etc. contain. But wholes and parts are always relative to a particular point of view. In an absolute sense, they are all objects and are, as such, elements of a set. The number of elements in a set can also be subject to regulations. The distinction between the two aspects of cardinality is expressed by placing the corresponding numbers in characteristic positions. The letter n indicates that no a priori limit exists for the number of objects, either as parts of a whole or elements of a set. The letter y (see illustraton 8) is reserved for the designer's indecision; apparently, he still has to decide on cardinality.
About the set concept, and with respect to what has been written before, I add the following remarks. A separate person object in its turn constitutes a set for its parts. In this way, and according to the third modeling alternative, the extravert and introvert objects, both taken as roles/attributes of a person X, are elements of the object person X as a set. Any object can be considered a set (a whole) containing randomly taken other objects as its elements. A class-as-type, however, is only a set for those objects that are typed by it. It is the experience of behavioral diversity exhibited by one and the same object that makes the designer aware of the necessity to view roles/attributes as parts and/or as specializations. With truly disjunct roles ànd also when each and every role is independently identifiable from the outside, such roles may be modeled as subclasses for specialized objects. As soon as the independent identity of a role is questionable, the designer must choose for an information model in which only an overall object can be logically invoked through an outside message. As a part, of course, the role object can still be a specialization. It will be unlikely, however, that the class of the object of which it is a part will be the relevant generalization.
The approach of Coad and Yourdon is limited because, to put it very generally in my terms, they consider the structural classifications of generalization/specialization and whole/part as mutually disjunct. By keeping these classifications strictly separated, they do not offer a view on opportunities with object orientation that require just their interplay.
For simple information systems such interplay for modeling and design is, indeed, too advanced. But where do simple conditions still hold in an information society that is developing fast? As information technology is applied in situations with growing complexity, a designer is more likely to need models with objects that maintain their integrity but can also exhibit diverse behaviors. That is a major design challenge, not only for the future but already for the present. The designer with his paradigm must be equal to the task.
In modeling classes and objects, I project a continuum. At one side, the abstract classifications based on generalization/specialization and whole/part can be applied completely independently from each other. The other side of the continuum represents a complete overlapping of both classifications. This would mean, first of all, that there is an object A that envelopes another object B. Secondly, and at the same time, the class of A would be the generalization of the class of B as a specialization. This complete overlapping, which in my opinion is highly improbable, is illustrated below. Still within the realm of the probable, could be a further elaboration of a role. For example, from a generalized concept of introverted behavior it can be imagined that more specialization of behavior is developed. Then, simultaneously, objects of the subclasses are parts of a whole that is an object of what from the point of view of the subclasses is a superclass.
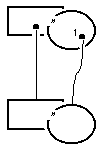
illustration 8
Somewhere along the continuum, the designer has to make decisions about the relationships between classes and objects. It seems simple enough to limit information models to mechanisms at both ends of the continuum. But in real life, with real information systems, such simplicity soon loses its attraction. Situations turn out to be more complex, different behavior requires conjunction within an overall object, etcetera.
It want to make absolutely clear that choices along the continuum of (non)-overlapping of classifications do not correspond to what is called multiple inheritance. For inheritance, only the classification of generalization versus specialization is relevant. Distinguishing between a whole and its parts is completely independent of inheritance. Whole/part has to do with a set and its elements whereas inheritance is a 'typical' typing concept.
At first glance, Coad and Yourdon, and others who serve the same market of practitioners with popularized ideas, offer a promising approach using object orientation. But a designer who does not move beyond their — use of the — paradigm can never achieve results that improve on what was already possible with earlier information technology. This probably explains why critics of object orientation talk about OO being "nothing new" and fail to support let alone apply the OO paradigm. Looking at all the hype, I often agree with critics that claims made in the name of object orientation are exaggerated. Being often unfamiliar with basic tradition in information systems, enthousiasts try to outcry criticism with new and more extravagant claims. I want to try to deal with criticism realistically. As I already said, I feel that object orientation offers nothing radically new or different. But it does offer some additional, mostly conceptual tools which support modeling for complex information systems. That is a definite gain. As also becomes manifest through this exposition, it is not always simple to make finer points clear to open the way for a paradigm shift, radical or non-radical as it may turn out to be.
An advantage Coad and Yourdon also fail to elaborate is the encapsulation of objects that are parts of a whole. It almost feels like they are afraid of the implications of recurrence. The result is that all their models based on the whole/part classification do not go beyond entity-relationship models. And in this respect, I find their use of symbols outright misleading. For it should be absolutely clear that an object-as-part is completely encapsulated in the (other) object-as-whole. I propose a different notation. See, among others, my illustrations 5 and 6.
Only attributes are given an unmistakenable position in the models of Coad and Yourdon. Of course, that is insufficient by a long measure to illustrate the specific opportunities of object orientation. By the way, according to the OO paradigm, attributes or, for that matter, purely descriptive roles, are in their turn also objects. It is just that the designer, by calling something merely an attribute, does not expect the extension of the whole/part recurrence. In my illustrations, I have tried to be more explicit about the important aspect of encapsulation. I strongly advise the most consistent application possible of encapsulation. A designer who is concentrating too much on generalization/specialization as a means for efficient typing of behavior will probably miss the special opportunities object orientation has to offer in the realm of consistent encapsulation on the basis of a whole and its parts. In principle, this encapsulation can be repeated indefinitely. Wholes and parts maintain a potentially recurrent relationship.
Reviewing their examples, it seems that Coad and Yourdon are bent on limiting encapsulation at only one level of recurrence. And that coincides with the level of attributes inside the object. As soon as an attribute qualifies to be embodied as an object, their models take the shape of traditional entity-relationship diagrams. A relevant question is here: "What is the difference between such diagrams and relational modeling with its corresponding normalization?" My answer: "Actually, nothing." I conclude that their superficial treatment in models of wholes and parts does not advance beyond the level of beginners. For real, complex information problems something more is required of a paradigm for object orientation.
There is a real need for experienced designers to research imaginary and real problems in the field of information systems for complex organizations and processes. Sorting out the problems, designers have to look for really effective solutions.
The danger of simplified introductions to object orientation is that they may actually lead designers in the wrong direction. Another problem, of course, is that not everyone who writes a book, an article, etcetera, also knows what she or he is writing about.
I return to problems with information modeling that occur often enough to claim attention. I refer, as always in this exposition, to the reality of conjunct behavior. A designer should model the pertaining roles not so much as specializations than as parts of the object that provides the identification for addressing messages from the outside. That they are parts is a minimal requirement. To what extent roles can also be specified as specializations, is a decision along an altogether different dimension, as I have outlined above.
When it is necessary for parts to exhibit extensive behavior in their own right they should be defined as objects (and not just attributes). But being parts, they are never objects that stand entirely on their own. As a minimum, they are always completely encapsulated by the whole of which they are parts. If there is no need for an extensive behavior, an attribute may be defined a variable instead of a full-blown object.
To continue with the earlier discussion, what is now the fundamental difference between the first and the third modeling alternative? In the first alternative, the roles appeared as completely independent objects. According to the third alternative, the roles are parts of a whole. Only the whole has an identity for outside objects. So it is to this object-as-whole, for example to a certain person object, that a message is sent.
As I have shown, conjunct roles in the disguise of disjunct specilizations make duplication of typing definitions, if not of actually stored information, inevitable. This danger has disappeared with roles as parts of a whole. For what the role objects for extraverted and introverted behavior have in common is shared through the behavior of their whole, in this case of the overriding person object. And because of their mutual residence inside one and the same person object, such specialization towards roles was not justified in the first place. Being encapsulated, the relationship between a part and its whole is guaranteed. See especially illustrations 5 and 11.
9. Situation as operand
Again, what are the benefits of the third alternative with its mechanism to approach internal objects (the parts) through an overall object (the whole) with an outside identity? Corresponding to the difference between situations, within each internal object (a part) variables and methods are limited to a specific situation that calls for the behavior in question. Such a model reinstates, for every specific situation, the desired uniqueness of variables and methods. This follows from the situation being an operand in the message that the encapsulating object receives and then, through postdifferentiation, sends on to a certain part object. A single conditional test by the encapsulating, overall object is sufficient to route the message. See illustration 9.
(person x, <situation>, do you love me?)
if the situation is
familiar:
(extravert x, do you love me?)
if the situation is
strange:
(introvert x, do you love me?)
illustration 9
Of course, in this follow-on message the situation as operand can be left out. This is a case of predifferentiation. For the part object that at the next stage exhibits the specific behavior, the situation no longer has the status of a condition that has to be tested upon by the procedural make-up of a method covering all situations. For that particular part object, the situation is implied (and all processing within the part object is again, of course, of a postdifferentiating nature to be handled by a simpler method).
Shifting the contents of a conjunctive role in the form of a disjunct specialization (alternative 1) to a role-as-part of an object-as-whole, requires every message to contain as operand an indication of the relevant situation. The object sending a message needs to distinguish between such relevant situations. Of course, this is not an additional requirement. But now, in terms of the third modeling alternative, it can finally be more formally stated that every object should reflect the variety of its environment. Translating variety into a domain of situations seems to be a more elegant solution than ending up with an empty superclass and several, specialized subclasses that — often ineffectively — represent something like completely independent roles.
Routing a message to the overall, encapsulating object that corresponds to an integrated identity is, using alterative number three, not the only way to invoke a person's role like extraversion or intraversion. Such roles are also objects in their own right, even as they are parts of a whole. Every object can be approached directly. The extravert role, for example, is only an internal object from the perspective of its whole. On its own, it is just like any other object with a unique identity.
Approaching the part directly, rather through a whole, requires that — instead of a specific situation — the whole in question is specified in the message. This enables a part to test whether it should respond by looking at the whole of which it is a part.
Of course, this option does not provide direct access. It could be that all relevant objects must be addressed sequentially until the one that should respond is discovered.
10. First intermezzo: taking stock
So far, the current paradigm for object orientation was left intact. All three alternatives for information modeling remained within its boudaries. I critcized the paradigm's application in the more popular literature on object orientation. Already, many improvements are possible without shifting the paradigm. A designer should just apply generalization/specialization and whole/part with due respect for the complexitiy of information systems in organzations and processes. Popular literature only deals with trivial examples and, therefore, does not scratch more than the surface of complexity.
The third alternative, although it already exhibits many traits of flexibility that I consider necessary, has a major shortcoming. I mean the conditional test, actually a procedure of postdifferentiation, that the object-as-whole has to perform, every time it routes a message to one of its parts. Such a routing method is inevitable for such objects, as every object belongs to one, and only one, class. The first text line (a message) of illustration 9 corresponds to the procedure shown in illustration 4.
Is there a solution to this problem? Can invoking a part be accomplished without a method in the object-as-whole? As I see it, the shift revolves around removing the limit of putting an object, as far as its behavior is concerned, in exactly one class. Here, of course, I mean class as a type and not as the set of which it is an element; following the current paradigm, an object can already be an element of many sets.
When an object is also allowed to belong to more classes (types), an implicit mechanism for selection of behavior is established. For this mechanism to work properly, it is necessary that the relevant class is known. Or, as I call it, the relevant context. This multicontextual predifferentiation replaces the explicit postdifferentiation that is still required by the third modeling alternative. However, multicontextual predifferentiation is beyond the current OO paradigm. Therefore a shift to a multicontextual paradigm for object orientation is required.
The remaining part of my exposition is dedicated to an introduction to a paradigm for object orientation that does not set a limit for the number of classes-as-types for a certain object. This multiplicity serves as the most direct approach to ensure the possibility of diverse behavior while maintaining the object's integrated identity.
The first part of this paper was used to establish the need for behavioral diversity of one and the same object that is confronted with equal messages but in different situations. In view of the current OO paradigm, the shift to multiple classes is a radical one. I award axiomatic importance to specific object behavioral acts according to different situations. In terms of my ongoing example, this means that the person holds central identity and not its possible roles. By changing a previous exception into a ground for general rules, the designer can model complexity more realistically.
There are many practitioners who consider object orientation as just another means to their end of raising productivity of development and maintenance of computer programs. They will most likely be unable to appreciate the shift from uniform to — the potential of — pluriform behavior following an equal message.
Here, again, I stress that the multicontextual OO paradigm is fundamentally different from the mechanism of multiple inheritance. In fact, the multicontextual paradigm more or less envelopes multiple inheritance but eliminates its ambiguities.
Multicontextualism should also not be confused with polymorphism. Polymorphism is about different behavioral acts of different objects, even when they have all been sent the same message. Actual behavior is based on the specific interpretation of the message, as the receiving object's class-as-type prescribes. The multicontextual paradigm still supports polymorphism. In addition, one and the same object can exhibit different behavioral acts in reaction to messages that are equal with the exception of an extra operand to specify a context.
Inheritance, be it single or multiple, and, to a lesser extent, polymorphism are seen by many developers as critical for raising productivity. I hold an almost opposite view, warning developers to be extremely cautious with whatever inheritance. I do not consider the mechanism of inheritance, which is a typing hierarchy along the dimension of the generalization/specialization classification, at all fundamental to object orientation. This explains why I do not pay much attention to inheritance. Lest complete silence about this mechanism creates confusion, later on I do offer some remarks. See the paragraph titled: About classes. I urge the reader to consider all I mention on inheritance, not so much as being necessary to found the multicontextual paradigm, but rather as side-remarks. I do not start from inheritance but from the need for flexiblity of information systems. A possible mechanism to optimize, for example, development productivity should always leave optimal flexibility of the end result intact. I am afraid that many developers today apply object orientation for their own, immediate gains, producing software and systems of lower instead of higher quality.
11. Read literally: object oriented
Inheritance implies modeling objects into hierarchically structured classes. Again, I stress that both classifying objects into classes and, in case of a hierarchy, the resulting inheritance are not fundamental to object orientation. I deny such a position, even though wide-spread practice holds it to be valid. If class were such a fundamental concept, object orientation should be called class orientation. Now, that is a shift I would not recommend.
Classes are means to the end of object orientation (object orientation being a means to the end of ... etcetera). It is as simple as that. Often, classes as just means that do not fulfill their purpose. Again, I refer to inheritance. There are risks involved. Through specialization, encapsultion can only be imaginary. It occurs when variables/methods have already been defined for a more general class, that is, higher up the typing hierarchy. The necessary overview is not too much obstructed when there is just a single definition. But what happens to objects in more specialized classes when the definition of a general class is changed independently? Are all the effects on the specialized classes considered? Can they be effectively managed? In my opinion, the current OO paradigm does not offer guarantees for maintaining consistency. My limited objective here is just to point at the risk of inheritance and thereby, say, un-stressing its importance.
What object orientation really is, what it can really contribute, will only become clear when the object is taken as the fundamental concept. The multicontextual paradigm is even more demanding in this respect than the previous paradigm. Object orientation is, first and last, about objects.
It helps to take the word object as literally as possible. Class is only a derived concept. Therefore, in what follows I continually put objects first. Then, how I look upon classes for typing behavior falls automatically into its proper place.
12. A practical occasion
Enough has been explained to transfer the exposition from the current to the extended paradigm for object orientation. Understanding is greatly assisted by knowing the concrete occasion which gave rise to an important step in developing a multicontextual view for information modeling.
As I am a practicing designer, I feel the need for a better theory coming up when faced with a practical problem for which I do not yet seem to have an adequate conceptual framework (read also: paradigm) available. In this case, it was a problem I encountered at a publishing house. One of its magazines had a single sport as its subject matter. To strengthen the position of this already dominating magazine, the publisher saw opportunities to bring, what he called, a comprehensive database to the marketplace.
Comprehensive? I asked what he meant. The answer was: "Well, everything."
My first task was to convince the publisher that such a specification is, to put it mildly, somewhat unrealistic. Computers, programs and databases do not work miracles. They never do. "Everything" does not exist with information technology.
But at the same time, I recognized a challenge. I thought I could show how to realize storage and retrieval of widely diversified information. The essential problem, in my view, was the impossibility of a unified structure for all pertinent information. I increased the challenge by broadening my attention from the one sport in question to include all sports. By now, of course, I was indeed looking for an information model of "everything."
13. Initial prototype
I decided the problem was so complex that it needed a practical protoype for further research. But, of course, even to develop a prototype, I needed a design. What model of the relevant information would I start with?
Fascinating about the countless sports and games is that they manifest exemplary variety. And any relevant information system, a database for example, must reflect this variety. So, it was immediately clear that it is impossible to design a detailed pattern where information about all such divergent human activities properly fits.
Now, what is important about the previous sentence, is that I connected the adjective detailed to the noun pattern. Indeed, such a detailed a priori pattern is impossible to conceive of in the face of overwhelming and ever changing variety.
So, what is the most promising direction to look for a solution to this formidable information problem? I did not find further refinement of the pattern at all atractive. The logical conclusion I drew from the infinite variety was that I would end up with specialized information structures for almost every detail.
Where variety is beyond practical enumeration, the only reasonable patterning direction is to go, first of all, from concreteness to abstraction. A more general pattern will hold all relevant details. But holding is not enough. Because specialization has been lost through abstraction (generalization), secondly, the general pattern must allow for a description of its relevant specialization to be included along with the concrete information that is registrered. Storage, retrieval and presentation of information should be based on such handling of specializations.
As I was facing the enormous variety, I opted for extreme abstraction. I had already, actually, carried this idea around for a long time. But now, here, was this practical occasion to apply it and work on it. In Ivar de Jong I found a software developer who gave the extreme, radical abstraction operational shape from the very first prototype on.
And the publishing house? It soon set different strategic priorities. The plan for their database was off. Never mind. I continued to pursue concreteness through abstraction on my own. The problem had caught me.
14. The syntax (form) of the abstraction
In my information model, I did not assume anything about the contents or meaning of the information. In other words, there was not a priori specialization patterned. As a consequence, the protoype that De Jong developed forces the user to a posteriori definition of specialization of information, that is, at the time of registration. Actually, the prototype was (almost) all form and no content. Or, in other words, (almost) all syntax and no semantics. Some minimal content is always resident in whatever structure. See Ellis. And as such, of course, a proposition like "the syntax of the abstraction" is problematic. Every abstraction needs semantic additions to support communication of concrete information.
Anyway, what form or syntax did I design? Well, at once both extreme and trivial, my model was limited to only one kind of entity or object. And this design decision has not changed and will not change.
For practical purposes, often several aspects of an object are relevant. So, one or more attributes must be included. How is this with a model where just one type of object is allowed? There is no problem when, also for an attribute, the choice is limited to what is essentially an absolute type for objects. The object representing the attribute is, of course, encapsulated (whole/part) by the object that apparently needed an attribute to elaborate relevant information.
Applying this same relationship, attributes can be refined indefinitely. In practice, recurrence comes to an end somewhere fairly soon but this principle of infinite recurrence should not be violated. It secures flexibility. The syntax of such radical abstraction requires, as I said before, just one class. It is as if the classification of generalization/specialization has disappeared.
Practical application of the syntax of the abstraction I propose, evolves into a whole/part hierarchy of objects. Illustration 10 shows a partially developed information base. (I call the extension of an information model with concrete information an information base, not a data base.) What is important to appreciate is that all such illustrations reflect examples, nothing more. It is fundamental to observe that they are all build from identically structured building blocks. The abstract syntax does nothing else than to prescribe that a particular block be filled with a unique object identifier (value) accompanied by an indication of the specialization (denominator) that is relevant at the position where the object appears. The syntax also rules the relationship between objects at neighboring levels (whole/part).
I must add that representing an information base as a hierarchy, such as illustration 10, could be misleading. The objects do not stand completely on their own as, for example, entities in an entity-relationship model. So, tree structures seen as consisting of completely independent objects would give the wrong impression. Following my design guidelines, an object encapsulates all related objects at lower levels. Earlier I made similar remarks about the use of symbols in illustrations.
Another note on symbolic convention. Tree structures are presented here upside-down. So, visually, the root is always at the highest level. Information is elaborated at ever lower levels of the hierarchy. As a level is shown lower in an illustration, the number (positive, integer) to indicate that level is accordingly higher. The same relationship is defined for information. Information of the highest order. i.e., information shown at the highest level, is indicated by the lowest number. As the order of information lowers, its index increases.
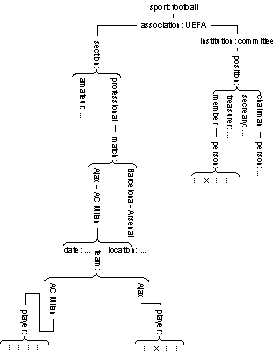
illustration 10
I repeat that illustration 10 is supposed to highlight applied whole/part classification. The hierarchy of a tree structure is merely used because a myriad of information can still be clearly differentiated. In illustration 11 the same information base is shown, now with emphasis on recurrent encapsulation.
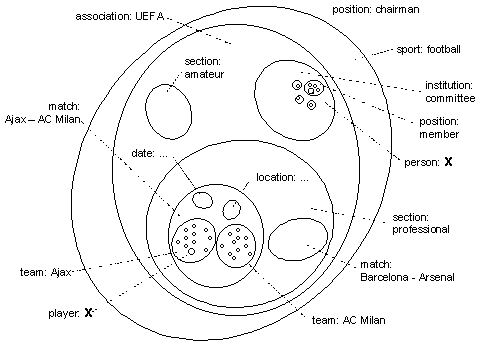
illustration 11
The syntax (form) of the abstraction I modeled is based, on the one hand on an object being autonomous (a whole), on the other hand on the object's potentiality to appear as an attribute (a part). Such attributes in their turn, are objects of the same, absolute type. Using the prototype, it was indeed possible to model the most diverse phenomena into a consistent information base, giving the information a structure to make later retrieval meaningful.
15. Second intermezzo: philosophical inspiration
Designing for concrete diversity through radical abstraction often is a lonely enterprise. Most people want right away to be specific and concrete. They do not understand what extra opportunities abstraction may create. I was, therefore, happy to find support with the philosopher Ludwig Wittgenstein for the attention I paid to abstraction. He wrestled with language and, among many other aspects, with the variety that people seek to express with it. To connect my own model to the ideas of Wittgenstein, I refer to what I said earlier about the impossibility of an a priori detailed pattern for information and then, more specifically, in view of the enormous variety of sports and games. Wittgenstein writes (p 31e etc.): "Instead of producing something common to all that we call language, I am saying that these phenomena have no one thing in common which makes us use the same word for all, - but that they are related to one another in many different ways." What I find especially inspiring in view of the practical occasion I mentioned to pursue abstraction in order to be more concrete, is that Wittgenstein writes about ... sports and games. His question is: "What is common to them all?" He continues by answering that similarities may be compared to the way that fibres together form a thread. "And the strength of the thread does not reside in the fact that some one fibre runs through its whole length, but in the overlapping of many fibres. [...] Something runs through the whole thread - namely the continuous overlapping of those fibres." My own model is based on the assumption that much information on sports and games shares the syntax (form) of a radical abstraction. And because the variety of sports and games already seems infinite, it is likely the model will hold for much more information. I do not see any obstacle why the model's application should only be limited to the ocasion that gave rise to its formulation. For at a very early stage in my thinking, I even abstracted from sports and games. Wittgenstein's ideas supported my design direction. I hope that my experience helps other designers to be aware that philosophy is not just theory and therefore useless for their so called practical purposes. On the contrary, a good theory is indispensable for those who aim to be practical.
16. Denominator and value
The essence of the information model or, rather, of the syntax of the abstraction I designed lies in its reconciliation of autonomy and 'attributeness' of an object. Let's start with a completely autonomous object. Adding objects, it is possible to introduce attributes of the original object. Then, adding attributes of attributes ... and so on.
Each attribute is also an object; as a part of a whole it does not stand completely on its own but is still an object like all others.
The recurrent nature of the — structure of the — information model, i.e., before any concrete information base is developed from it, makes it sufficient for a formal statement about the syntax to describe an object and its relationships at a random level, say at level n. Corresponding to an object positioned at level n is information of an order n.
Suppose a particular object, representing a person, for example, appears at level n in a hierarchy. Taking a hierarchical look at the information, the immediate attributes of the object have their structural position at the next lower level, that is at the level indicated by the number n+1. (Convention: a lower level in a tree structure, in an illustration as seen from the top, corresponds to information of a lower order as indicated by a higher number.)
However, just introducing additional objects at level n+1 does not close the gap with the variety to be covered. For example, the objects identified by blue, 38 and 71, respectively, contain some information. But what kind of attributes are involved is still left open. The information at a particular position in a tree structure is only complete when an attribute contains both a denominator and a value, where the value is taken from the domain of the preceding denominator.
It is, actually, the value that identifies an object at the next lower level or, what amounts to the same thing, information of the next lower order. In this way the value 71, for example, is preceded by the denominator weight. And 38 could refer to shoe size. This simple example with information of two orders, or objects at two levels, is shown in illustration 12.
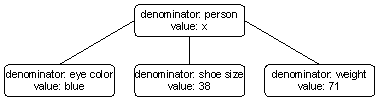
illustration 12
Every denominator in illustration 12 is followed by just one value. Already in illustration 10, it is visible that multiple values after a single denominator are allowed.
Reading illustration 12 in the opposite direction, the top level needs some explanation. The (identification of) a person also has value status. It is preceded by a denominator identifying the object in exactly that particular position as a person. It was, therefore, too fast to arrive at the conclusion that the value must pertain to a person. The right reasoning is that a value identifies an object. The denominator is necessary to qualify the object at that particular position in the information base, for example as a person.
By now it should be clear that through the addition of denominators, a mechanism is available to differentiate between behavioral acts of one and the same object according to its multiple positions in a structure. In illustration 12, the denominator of (object) X is person. Somewhere else it could be player. Or employee. Or even statue. Etcetera.
Continuing with player as a denominator, it is easy to imagine information of lower and higher orders. Of a lower order, that means higher up in the hierarchy, information could identify the player as belonging to a certain team. The denominator of order n-1 would be team and the information following it at that level the identification of an object that in this particular position counts as what the denominator says it does: an occurrence of a team. Somewhere else the same object could be denominated as, say, an organization, or an orchestra.
By moving further up the hierarchy of a tree structure, it is possible to model the team being a part of a club. Upwards, the normal limit is always information of the first order. As far as formalization of the syntax of abstraction is concerned, beyond that boundary conditions must be defined. Which object is it, if any, that has the objects at level 1 as its attributes? What counts as the root of the whole tree? My formal definition is that the complete information base serves as a so called original object. As such it is information of order 0. Or, the (only) object positioned at level 0.
The complete information base is the only object that is not an attribute of another object. All other objects are parts of at least one other object. Also, an object at level 1 never stands completely on its own. Minimally, there is always one preceding denominator. What denominators of the first order represent is nothing more or less than the whole/part classification that is considered most fundamental for the purposes of the particular information base.
At first sight, a denominator corresponds to a class. And a value to an object. But, on purpose, I have chosen terms different from class and object. As I will explain shortly, the extended, multicontextual OO paradigm allows for a class to be determined by more than just a single denominator (whereas the current OO paradigm allows an object just a single class-as-type and a single 'denominator' to indicate it). And my concept of a value mainly serves to identify an object within a certain context or, in an output oriented manner, present the object to someone who is interested in the information in question.
In an information base, and applying my design for multicontextual object orientation, any object always contains more information. First of all, an object contains all of its attributes as required, plus all of its contexts. Below, I explain more extensively what I take to be a context. And what it means that every objects contains all of its contexts. Here, I already mention that the minimal context equals one denominator (which is, at the same time, the minimum and maximum context for the current OO paradigm). Preceded by a single denominator, a value is information of order 1.
As before, I realize that my discussion can cause confusion because I offer concepts in a different configuration (which, actually, is a definition of a new paradigm). Of course, I will try to dispell confusion as much as possible. At this point, I am concerned about the relationship between an object and what it is supposed to represent. Please recall that I did not offer formal propositions on this problematic relationship. What I rejected was a position that philosophers refer to as naive realism. Actually, an information object does not so much represent as project a reality.
Where reality and information meet according to my extended OO paradigm is strictly at the axiomatic base level, that is at level 0. Starting from there, all my other formal propositions about the information model are strictly limited to (relationships between) objects that exist inside the information base. As a concept for my exposition, an object is always and only about information. I restrain from real world propositions, at least from formal propositions.
Of course, I am totally convinced that a real world exists. It is only that I do not attribute absolute existence to many objects that appear in models and their extensions. So, whenever I use the term object I do not intend to refer, at one and the same time, to both a signifier carried by my syntax of abstraction and a signified in the real world. That would, indeed, be utter confusion, a confusion, I am afraid, not every designer of information systems is sufficiently aware of.
17. Simultaneous emphasis on autonomy
The actual registration of information, again, I stress, inside the information base mainly follows a progression. The base grows as details, i.e., information of lower orders, are added. It always starts with at least one denominator and one or more values of the first order. Then, specifying attributes, lower orders are activated for as long as they are relevant for the information task at hand.
But adding information does not automatically imply creating ever new objects. I take up the example of the player. It should be clear that the denominator corresponds to what I defined at the start of this paper as a role. It turns out that role and denominator may be used as synonyms. The term role accentuates the dynamics of behavior, whereas denominator stresses a more static quality of an object.
As every value appears after at least a single denominator, it is fair to say that all objects always play roles. The only exception is the complete information base, and then only by definition.
Anyway, with more information in the base, chances grow an object has already been registered before. What needs to be added is the additional role and further attributes that are relevant to this new role. These additions do not change the object's identity. It both remains what it was before and changes only in detail. Its essential autonomy in terms of integral identity is not affected in the slightest because the object appears in numerous collections of preceding denominators and values. On the contrary, the more diverse the roles of an object, the more need exists for an integrating mechanism. Applying the multicontextual OO paradigm, it is completely transparent that one and the same person is known as a team player during a particular season, as a club member for an even longer time and, one almost forgets, as a person for the whole of his life. For each role, at a minimum the identifying value of the object is added. (Below I treat the case of equal values for different objects.) And everywhere attributes may be included, for example, whether the player scored a goal, was sent off or whether the club member paid his dues. Of course, attributes only hold for the role to which the object-as-value is currently connected. And the complete role is always determined by all denominators and values that precede the value in question in the hierarchy.
It is bad information management practice to register, say, date of birth at — the position of the — the role of player during a certain match. Here, another role offers an opportunity for the information to be managed without duplication. The optimal context for date of birth to be included in an object is, of course, person. Likewise, all information must be positioned so as to avoid duplication. That is nothing new for those who are, for example, familiar with normal forms.
When the optimal context is not yet available in the information base it must be created. This happens when at first there is only interest for who has scored goals, irrespective of the age of players. Broadening requirements leads to adding the role of person. In this case, it should be straightforward. A single denominator of the first order is adequate.
Illustration 13 offers an overview of several contexts, all pertaining to the same object identified by the value X. See also illustrations 10 and 12.
It is the value X that has multiple occurrence in the information base. The object this values refers to retains a singular occurrence. As such, it contains all its different contexts (roles) and all its attributes as they have been added at lower levels in the hierarchy.
Attributes may be multiple. The denominator person at the highest level can serve as an adequate example. It must be possible to include information about more than one person in the information base.
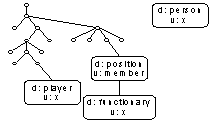
illustration 13
18. Behavioral forms
Avoiding duplicate information with relational sets is taken care of through normalization. The sketchy presentation, above, of limiting information to a specific role of an object resembles the development of normal forms to a large extent. But there are also differences between the two approaches. They are, of course, related to the opportunities and limitations of the relational and object orientation, respectively. In order to acknowledge the resemblance that does exist, I define the efforts to avoid duplicate information under the multicontextual OO paradigm: the develoment of behavioral forms.
The existence of behavioral forms indicates that the extended paradigm has its own characteristic 'normalization' process. What are known all over as normal forms should be considered as belonging to the relational approach only.
19. First behavioral form: uniqueness
At this point of my exposition, all concepts for my information model and overall OO paradigm are still largely informal. I would say this is a perfectly normal state of affairs. Formalisation follows after, never precedes, an informal start.
Anyway, I formally consider information to be in first behavioral form when the pertaining object has the opportunity for unique behavior. Every object, therefore, is uniquely ... itself. Or, put in yet another way, every object defines in itself always one class. For it is always a class in itself. This uniqueness condition is necessary to support diversity of behavior.
20. Second behavioral form: random identification
Every higher behavioral form presupposes all lower forms. Information in second behavioral form is, therefore, also in first behavioral form.
Beyond first behavioral form, second behavioral form stipulates that the object's unique identification is totally independent of any external information requirements. In other words, the object's key is entirely non value-based.
There are enormous advantages to an object having a random identification. Of course, I am well aware of longer access times to information where only the secondary access criteria may be stated in terms of external requirements. But I do not consider these problems as being insoluble. And the advantages of a random identification are fundamental. Without a value-based key, information can be modeled with much more flexibility.
The random identification, meaningless for interaction between objects and human users, has consequences besides longer access times (except internally when the random identifier is directly used as pointer). Other information than the identification has to be presented for purposes of recognition. The decision has to be for one or more values that are contained by the object. As a result, there is no guarantee for a unique interpretation. Suppose, last names are used as identifications (better: as values to re-present objects). Different persons can share a last name. The problem is resolved by signalling identical last names as values from different objects. Through closer inspection of those objects — in second behavioral form, of course, where their unique identifications are 'meaningless' —, the user can select the 'right' object. If no differences are apparent upon inspection of one, more or finally all other values, the question remains why more than one object was created in the first place.
21. Third behavioral form: object-in-context
One particular object, with a representing value X, for example, could appear at many positions in the information base. Illustration 13 shows three occurrences of X. Characteristic of the difference between the registered positions of X are the subsets containing specific denominators and values, their configuration included. All those denominators and values in a separate subset precede, so to speak, the position of the object itself, that is, before the object appears in the attribute of an object at the next higher level. That characteristic configuration of denominators and values is what I formally call an object's context. Every object, except the complete information base, is positioned within a context. And that determines third behavioral form.
The minimal context consists of just one denominator. It is the context of an object at the highest level in the hierarchy, i.e., at the level numbered 1.
The number of contexts of an object is at least one. It does not automatically follow that the level at which an object with just one context appears is level 1. Such an object could appear anywhere in the information base. What is valid is the proposition that an object with just one context has only one registered position. The corollary is that an object has as many contexts as it has registered positions in all of the information base. For, starting from a particular position of an object, its context is unique.
On the orther hand, two, or more, objects may share a context. This happens when those objects, at least their representative values, are all placed after the same denominator, the rest of the context already being equal.
22. Object: joining context with intext
A context corresponds to a situation. Aimed at pluriformity, an object may behave as diversely as there are different contexts established. In my view, this is autonomy taken to its extreme, and it needs the multicontextual OO paradigm as a conceptual framework.
A simple elaboration from such autonomy or, in other words, specificity of behavior that is dependent on context, lies in adding attributes. To contrast — information about — attributes against context, I define all information of a lower order, i.e., lower in the hierarchy than the object's position en therefore with a higher index, as intext.
An intext, of course, shows the familiar pattern of progression of denominators and values for as long as elaboration is found relevant. Any value of next lower order, i.e. lower in the tree structure, is an object in its own, autonomous right. But in one respect, it never stands completely on its own. For every object, excepting the complete information base, is always also a part of a whole. Anyway, extending information to a lower order/level always results in an additional context. This is a context for the object that is identified by its representative value at the proper position in the tree structure. A part object belongs to the intext of a whole object. Reversely, a whole object belongs to the relevant context of the part object. So it all depends on the particular position taken, on the point of view. As every part object can, at the same time, act as a whole object, the progression of intext may be infinite. It all comes down to the structural quality of every object, again with the sole exception of the complete information base, as follows. Every object at a particular position serves to join a unique context with an intext, where the intext should be considered an elobaration into attributes (also read: roles with parameters). It is the value in question, representive of a particular object, that connects one intext to one and only one context.
Again, the possibility of progression is infinite. For, excepting the overall information base, every object joins a context to an intext. Even an object for which an intext has not yet been included can be supplied with an intext at a later stage. Every object at any position has the potentiality for — yet more — intext.
23. Recurrence and formalization
What I call the syntax (form) of the abstraction is characterized by what I believe to be — a potential for — maximum recurrence. Whenever a start with an information base has been made, the whole pattern is created by repeating smaller patterns. To make a start means, first of all, to consumate the boundary conditions of the muticontextual OO paradigm, the whole information base being the exception to the formalism of recurrence. This exception is grounded in the axiom that the complete base does not qualify as an attribute of an even more comprehensive object. The top of the hierarchy has to be formally defined ex nihilo. My choice is to consider the complete information base not just an object represented by a value but also its own denominator. Then it simply follows that the complete information base is also its own context. Assigning order zero to the complete information base, the boundary conditions may be formally stated as follows:
if
denominatorzero = d0,
valuezero = v0
and
contextzero = c0,
then
v0 = d0 = c0.
Next, all (other) contexts, from the point of view of an object's position at level n, are decribed by a straightforward formula:
cn = (cn-1, vn-1, dn).
Of course, this formula is valid for every n greater than zero.
24. Fourth behavioral form: contexts-in-object
An object maintains its autonomy even where it displays the most diverse behavior. What is, therefore, unique in terms of behavior, is the object-in-context.
Concepts like situation, role and context are all closely related. The context corresponds to a situation and, as such, is the basis of specialization according to a particular role. Multiplicity of contexts allows for diversity of behavior. As a guarantee, an object in third behavioral form is not only in second behavioral form but should also be completely familiar with all its relevant contexts.
By turning the words around that I used to typify third behavioral form, the fourth behavioral form comes into focus. Of course, first of all, the fourth presupposes the third behavioral form. Then, in addition, an object is not only familiar with all its contexts but also encapsulates them. All relevant contexts are contained within an object in fourth behavioral form.
At first sight, the condition of an object containing a context may look absurd. For example, how can a person contain his environment? Well, the answer is that he does not. What should be clear is that a context is not equal to a situation but closely related. What constitutes a context is information about a situation or, philosophically less naive, a context projects a situation. And that is what is relevant here, just as a living, real person has within himself access to all kinds of information about his environment, pertaining to all kinds of different situations. That variety of information is exactly what enables a person to behave as different situations require. For this behavioral analogy I refer back to the second paragraph: Diversity of behavior. Elsewhere, I stressed that object is a concept that I use with respect to information and not to 'objects' in the real world. My point is that context is also information, ready to be formally ruled by the same syntax of abstraction.
Fourth behavioral form is what most clearly distinguishes the multicontextual OO paradigm from the current paradigm. And then, of course, multicontextualism only becomes evident with information of lowel orders than the first, i.e., with higher indices.
Information limited to the first order still seems to follow the class concept of the current paradigm for object orientation. But even with information of the first order, there already is a difference. According to the multicontextual paradigm, one and the same object may be positioned after several denominators and, by implication, 'knows' several contexts of the first order. So, even limiting the information base to the first order, the possibility of behavioral diversity exists. It is exactly this diversity that separates the multicontextual paradigm from what went before under the name of object orientation.
In fourth behavioral form, every object contains all of its contexts. Of course, this is a digression from the traditional whole/part classification but that is not what I want to discuss at this point. I continue to demonstrate the resulting mechanism for diversity of behavior.
A message refering to a particular situation can be tested for available (components of) intexts and contexts. Whenever an intext contains a relevant object the original object can transfer a modified message. Or, when, on the other hand, its context shows itself to be relevant the original object can continue with the message itself. Which method is chosen, of course, is dependent on several factors such as name of method and other arguments given in the message.
So far, fourth behavioral form already goes much beyond what I mentioned as the third modeling alternative using the current OO paradigm. See the first half of this paper. Another innovative step is to match contexts with classes. Then, conditional processing of (the relevant parts of) the message by an explicit method of the receiving object is no longer necessary. Instead of a method which implies postdifferentiation, there is the opportunity for predifferentiation. The focal point must be the object as it joins contexts and (possible) corresponding intexts. Equivalence of or, at any rate, a close relationship between class and context enables an implicit mechanism of method selection, i.e. of predifferentiation. This also makes the information base more adaptable, more flexible. Any new contexts and/or intexts do not have to be explicitly specified and added into methods. Declaration of a new context-as-class, or of some components of a context as constituting a class, is sufficient.
25. Fifth behavioral form: a necessary and sufficient condition
Actually, I take it for granted that an object contains its intexts. A behavioral form dedicated to this range of encapsulation should, therefore, be unnecessary. But I do propose yet another behavioral form in order to stress the extension of information by adding attributes through denominators and values (values being representatives for objects positioned at the lower hierarchy level etcetera).
Because of the recurrent nature of the syntax of abstraction for multicontextualism, the question should be asked whether an object must contain its complete intexts. Or, is a logical subdivision possible that limits encapsulation while maintaining the requirement for completeness of intext? What is a necesary and sufficient condition that makes any intext at least logically an integral part of a particular object?
It is necessary and sufficient that an object contains, through corresponding denominators, the values as information of the next lower order (or: objects positioned at the next lower hierarchical level). This is a necessary condition for without it attributes would be missing.
It is also a sufficient condition. This holds because the original object is always part of the context of the object that is now positioned at the next lower level. Suppose that the object at the next lower level is also extended by some intext. First of all, such an extension is at the same time a further extension of the original object but at levels once removed, or even more. Then, further extensions and original object can always be related through the context of the object at the next lower level (as seen from the original object). To limit intext to next lower level objects only, i.e., to information of the next lower order, therefore, is a sufficient condition for logically complete encapsulation of intexts.
Any object that is in fourth behavioral form and, in addition, limits encapsulation of intext to information (denominators and values) of the next lower order is in what I define as fifth behavioral form.
All in all, three points of view are relevant from which to consider an object. First of all, the object works to join a particular context with — if present in the information base — a particular intext.
Now suppose another object is taken as connecting a context to an intext, then a second point of view shows the object in question as part of a context. An object can be part of a context when the other object is at the second or at any lower level.
The third point of view, again given another object to join context with intext, shows the object in question as part of an intext.
Looking from the object that joins context and intext upwards to the top of the tree, the particular context is always unique and consists of a trail of pairs of single denominators and values. It is unique because contexts from the same position can not, by formal definition, overlap. And that the trail upward consists of single occurrences of denominators and/or values at every level follows from the branching structure of the tree. From top to bottom, there is multiple choice. The other way around, that is, from a single lower position to the top backwards, a straight line results. And again the patterns are recurrent. For example, every intext is (potentially, i.e., dependent on the actual eloboration of information) a tree structure itself.
The absolute linearity of context on the one hand and the tree-structuredness of intext on the other, are recapitulated in illustration 14. The value X or, rather, the corresponding object is apparently registered three times, every time within a particular, unique context. By highlighting contexts and intexts from the first point of view, is it easy to recognize the object as joining contexts with intexts at three different positions. What illustration 14 sets out to accentuate, by the way, is this object-as-connector. The object is not illustrated in fifth or even fourth behavioral form.
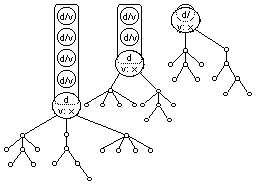
illustration 14
Illustration 15, below, does not distinguish between values and denominators. It should be read starting with the object that is presented (if not identified) by the value X. To avoid cluttering the image, there just one context appears and also a single complete intext to go with the object in the particular context. Apparently, attributes were required for the situation to which the context corresponds. In order to demonstrate their interdependence, both context and intext are supplied with the same indexing subscript: i.
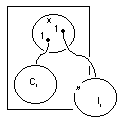
illustration 15
Illustration 15 also tries to show, informally for now, that (a certain part of) the context and the object-without-its-intext together exclusively typify the intext. This is equivalent to stating that context plus object determines a certain class. I continue this line of reasoning in the paragraph titled About classes.
For purity's sake, I remark that object X is not portrayed in fifth behavioral form; the complete intext i within context i is meant to be shown. Of course, when the intext i does not cover more than one order/level, an illustration of fifth behavioral form would result. The number of objects that are typed as intext i is indicated as n. For, what counts as class, is dependent on what is taken from the context and the object itself to determine behavior. The more components of context and object are left out, the wider the range of such a class.
Illustration 14 clearly shows that a context should always be considered from a particular position upward and is, therefore, linear. These linear contexts are a consciously designed aspect of the syntax (form) of the abstraction for information modeling applying the multicontextual paradigm for object orientation. For information that has linear structure is optimally suited for retrieval as the example of relational databases with Structured Query Language (SQL) amply testifies.
Related to the linearity of the multicontextual syntax is recurrence. Taken together, a promising starting point exists to develop a query language for object orientation, an object query language or OQL, for short.
About the possibility of such an OQL to offer standardized simplicity for object queries and thereby making complex information bases manageable, I only remark at this stage that every object is part of one or more contexts. Through linearity of contexts and the paired singularity of denominators and values at each and every level, it should be possible to design a fairly compact syntax for information retrieval. A multicontextual information base, with objects in fifth behavioral form, should not only enable extremely flexible information modeling and registration but, and that is what information management should finally be all about, extremely flexible information retrieval and presentation.
26. Consistency along two dimensions
Above, I declared consistent encapsulation to be relevant for the recurrence of the multicontextual OO paradigm. An object's attributes are ... objects. In its turn, a lower level object can be assigned attributes that are objects, also containing objects-as-attributes ... containing objects-as-attributes ... etcetera.
A different meaning of consistent encapsulation refers to the whole process followed to develop information processes and systems, from initial design up to all the resources that can be used operationally. The encapsulation as modeled in original design should be left intact as much as possible in the information base and programs for operational application. To put it more succinctly, all models from infological to datalogical should be as isomorphous as possible. It is object orientation, especially the richer multicontextual paradigm, that can support increased semantic unity along the developement process. And it is precisely this need for fundamental semantic translations that hampers development with and results of more traditional information management technologies, relational databases and the current OO paradigm included. There, in complex cases, model isomorphism and semantic continuity are lacking. No serious problems arise as long as no attributes are required at levels of recurrence lower than the second. But, then, where lies the profit of moving to object orientation? The paradigm and prototype described here try to move beyond current restrictions. A major characteristic is the consistent encapsulation from design model to actual information base. In fact, the protoype serves an excellent purpose as a design tool where information can be tried in the most divergent configurations. As I said, it all started at a practical occasion where there did not seem to exist an elegant solution for the problem of diverse behavior of an object that had to maintain its integral identity.
27. About classes
As a designer, I consider a single, autonomous object as the external unit of behavior. When required, an object's specialization of behavior into separate roles is based on the concept of object-in-context. A number of contexts for the same object provide a number of corresponding behavioral acts. But does this mean that the class concept for typing behavior has disappeared? No, it has not. But starting from pluriformity, from diversity, demands treating class as a derived concept. So, why and how is there still a place for class in terms of typing behavior?
Many objects exhibit similar behavioral acts. As a matter of practice, it is convenient to limit behavior specifications as much as possible. Duplicate definitions are, and will always be, inefficient. It is still the class concept that provides a mechanism to share specifications etcetera.
The extended, multicontextual OO paradigm is not a departure from the practical need for efficiency. It is even possible to provide a more structural definition of the class concept under multicontextualism. Throughout this exposition, several remarks have already been made to this extent.
A class-as-type is constituted by the context, taken completely or a subset of its denominators and values, plus the object in question itself. The object itself, actually, is also a non-mandatory determinant of a class. When all of the context plus the object itself is relevant for its — type of — behavior, the object apparently has a unique behavioral capacity in the entire information base. This is diversity of behavior taken to its extreme and it should be included by a multicontextual OO paradigm. Not only is every object-in-context unique, but also its behavior-in-context should be potentially unique. Why? Maybe not even because it is such a realistic assumption but because it really works.
However, not all components of context-plus-object need be determinants of particular behavior. It could only be a subset that is relevant for typing. Now, in a certain context, suppose that the object in question itself does not count as part of its type determinant. This indicates shared behavior, i.e., to be shared between all objects within the same context. As I said before, the fewer components of context are determinants of behavior, the wider the typing influence of the corresponding class as more objects will be eligible.
The importance of pluriformity is given absolute, formal priority in the first behavioral form. For any object in first behavioral form is unique and autonomous, irrespective of any context other than its own existence. A single object is at the minimum a class completely of its own. Therefore, the multicontextual paradigm states that every object belongs to at least one class (in the sense of behavior typing; as an element, of course, every object also constitutes a minimal, non-empty set). In addition to the class-of-its-own, the object is subject to as many classes as are necessary to specialize its behavior through predifferentiation. The number of classes and contexts are not necessarily equal. The number of contexts is the theoretical maximum for the number of classes of an object. The multicontextual paradigm gives, along with object, of course, primary status to the concept of context. Class is not so much a fundamental concept, but derived for practical purposes. As such, its importance should not be underestimated but valued properly.
I also add a note on inheritance. I do not claim that the multicontextual paradigm combats the risks of inheritance. One context may be considered a specialization of another context. So I continue to warn against indiscrimenately typing behavior, using a generalization when dependent specializations exist.
28. Related developments
Activities in information science, like in other sciences before, have increased to such an extent that I do not pretend to be original. The mass of reported experience is so overwhelmingly great that I will never be able to supply adequate proof of uniqueness of my ideas. It is, therefore, perfectly possible for the multicontextual OO paradigm to have been articulated before, by someone else. Actually, I find such moderating statements to be valid for almost all of human activities. There will always be relevant sources left, I am sure, that were not consulted. Such uncertainty can be a formidable obstacle to communicate ideas.
So, instead of being paralyzed, I admit that I can never do more than scratch the surface of what has already been reported on object orientation. Starting from there, I tried to locate some related developments. A small selection of what seemed relevant from the literature I report here. It can help the reader to find his own way and support her/him to judge my proposal for a multicontextual OO paradigm and its information objects up to fifth behavioral form.
The best advice I have to offer is to consult not so much the literature about object-oriented information technology but, first of all, literature about behavioral diversity. Especially in the field of social psychology a longstanding tradition already exists of research into human beings and how they behave under different circumstances. Typical is Barker as he says (p 203): ["T]he behavior of the inhabitants of any [particular] setting is less varied than their behavior across all the settings they inhabit." Or, in terms of my example, the extraverted behavioral acts of two different persons are more alike than the extraverted and introverted behavioral acts of the same person. Fiske and Maddi conclude about behavior that (p v) "[v]ariation is the normal condition."
It is regretful that many information scientists and practicioners appear to exclude themselves from influences from other disciplines. In fact, they are often dangerously parochial. But also Wittgenstein's quotations should make clear that interesting thoughts are often already reported if only one takes the trouble to investigate. Of course, as I said before, it is an illusion to cover everything available. But it is often other fields and sciences that can provide extra inspiration. Designers, especially, should continue to actively look to develop their modeling abilities. They must concentrate on building powerful models, not on applying the same method over and over again. So, for designers of information systems, information science is only one out of many sources they must be familiar with.
Of course, many information scientists are also actively involved with interesting developments.
Durchholz and Richter are still leaving out behavioral dynamics from their data models. That is, they do not treat behavior according to any object-oriented paradigm. What I would consider static objects are called constructs in their approach. And a construct occupies a position or, as they call it, a spot (p 33) in a structure. Indeed, this part of their work closely resembles my own. A difference, among others, is that a construct refers to a limited articulation into components. My approach, on the contrary, is open-ended; elaboration into information of lower orders can progress infinitely. Such axiomatic infinity has led to extreme abstraction and on to a very compact syntax (form) for information modeling according to the multicontextual paradigm. In short, our results come out different though some aspects are very similar.
My ideas are also related to everything to do with binary data models. And to hypertext. What I suppose is unknown again to most information scientists is the relationship with so called facet analysis as developed by S.R. Ranganathan. His problem was in the field of documentation. He looked for new ways to classify diverse information. As I see it, information scientists have for too long neglected all such conceptual work for libraries and Archives. It can be really inspiring as explicit modeling of information for libraries and Archives has a longstanding, rich tradition.
And then my approach turns out to be closely related to work in semantic networks. The informed reader will have guessed so immediately after I introduced denominators and values that can be defined ad hoc. Ter Bekke offers an overview of several developments in information modeling and semantic networks. He argues for object relativity as being characteristic for the semantic approach to information modeling and supplies a definition (p 54). "The object relativity principle says: type, instance, generalization, specialization, aggregation and attribute are just different interpretations of one and the same object." Borrowing his definition, it shows that the semantic network approach is a subset of the multicontextual paradigm for object orientation, just as the relational approach is another subset. The multicontextual paradigm ensures object relativity by positioning an object in a structure according to - single concepts such as - denominator, value and order and - compound concepts such as - context and intext.
As a side remark, I take the opportunity to air an objection against semantic networks. I find it outright confusing to use semantic for an adjective and, therefore, in the long run even harmful to an otherwise valid and inspiring approach. That is probably not what whoever thought of the name intended. I suppose the name semantic network originated when some researchers thought that artificial intelligence with computers could equal or even surpass human intelligence. They thought the key to success lied in understanding language, human language. Enter semantics on the stage of information modeling. Today, information scientists should have a better grasp of syntax, semantics etcetera, of how problematic such concepts are and how they are interrelated. So, it is time to leave such confusing concepts behind where they have become an obstacle for further development. For a balanced view of all such linguistic concepts I refer to Ellis. Semantics, pragmatics etcetera are all aspects of communication, highly interrelated and always present in a characteristic but ever changing mix. That makes object relativity a better concept to deal with flexibility of what, actually, is never more than a tool for information storage and retrieval.
With the above defence of human intelligence I conclude my short report on literature and related developments. Many interesting activities, so much at least is clear, have taken place or are in some fruitful stage of develoment. Although I did not acquire absolute certainty that I am working new ground, I feel reassured about both the utility and the foundation of the multicontextual paradigm for object orientation.
29. Further developments
The paradigm of multicontextualism opens the way to management of information objects in fifth behavioral form. A working prototype demonstrates the feasibility of the paradigm's information model. Although I seriously attempted formalization, many concepts that constitute the multicontextual paradigm for object orientation are still quite informal. Increased formalization requires additional effort. This paper is meant to stimulate practical and theoretical developments by inviting contributions of practitioners and scientists. I have indicated the need for a paradigm shift and outlined a direction with some ideas. Can they be falsified? Do they stand up during all kinds of practical applications? Can the multicontextual paradigm be formally stated in algebraic terms? Etcetera.
As a next step, it seems logical to improve the prototype by adding the possibility of dynamic behavior. So far, the prototype allows only for storage of and retrieval from a static information base as a multilayered semantic network. An object-in-context can not be invoked to show active behavior. And working with the current version, in order to elaborate information, that is, for every object-in-context, not only a certain value must be entered but also the preceding denominator. Of course, this is true to extreme abstraction or, to borrow the phrase, object relativity but it is hardly practical. Now, intexts are often similar, at least the denominators in the attributes. The protoype should also be enhanced with a mechanism for providing the standard pattern of denominators for an intext, based on the particular context. This needs implementation of a modified class concept, one that supports the diversity of behavior. The paradigm should, however, continue to be about object orientation and not about class orientation.
Direct practical advantages can be gained through further development of the tools for information storage and retrieval. For such applications, an object can remain static, i.e. it does not need the potential to show behavior that requires methods that can be activated, for example, to pattern its intext. Already, for further development of an object query language, based on the multicontextual paradigm, the formalization seems advanced enough. The indeterminancy of a single intext which makes navigating it cumbersome, can always be exchanged with the linearity of one or more contexts. This is possible by moving down the hierarchy of the information base or, what amounts to the same thing, by lowering the order of the information. It all depends on the position taken. Where no more attributes have been added only the linearity of many contexts remains to be dealt with. The structure of context is suited for basic combinatory retrieval, comparable with relational algebra. The proposed syntax of abstraction, with its designed recurrence, offers the opportunity to develop a more generic query language than is currently available for object oriented information bases. Again, taken as a set of contexts, the retrieval process looks as straightforward as retrieval from a relational database. A most practical matter, of course, is whether retrieval is still completed within a reasonable time. Therefore, performance issues must also be addressed by further developments.
On the side of design, the multicontextual OO paradigm can support a critical re-appraisal. I feel that many designers commit themselves too early to irrevocable decisions. For example, what should be modeled as relationships are often taken as objects. That practice is typically inherited from entity-relationship modeling and normalization of information for relational databases. The multicontextual paradigm does not lead automatically to increased quality of design but it helps designers to be (more) consistent in modeling.
30. Conclusion
The current OO paradigm, or whatever paradigm, does not have absolute validity. There is always a need for improvement as additional requirements come into consciousness. As for object orientation, with this exposition I have brought multicontextual objects to fifth behavioral form. It is not meant as the final word on the subject. On the contrary, further developments are absolutely necessary.
literature
Ashby, W.R., An Introduction to Cybernetics, Methuen, reprint, 1979,
original edition 1956.
Barker, R.G., Ecological Psychology: Concepts and
Methods for Studying the Environment of Human Behavior, Stanford
University Press, 1968.
Berk, E. and J. Devlin (editors), Hypertext/Hypermedia
Handbook, Mcgraw-Hill, 1991.
Bertino, E. and L. Martino, Object-Oriented Database
Systems: concepts and architectures, Addison-Wesley, 1993.
Brittan, A., Meanings and Situations, Routledge
& Kegan Paul, 1973.
Cattell, R.G.G., Object Data Management: Object-Oriented
and Extended Relational Database Systems, Addison-Wesley, 1991.
Coad, P. and E. Yourdon, Object-Oriented Analysis,
Yourdon Press, second edition, 1991.
Durchholz, R. and G. Richter, Compostional Data Objects,
John Wiley and Sons, 1992.
Ellis, J.M., Language, Thought, and Logic,
Northwestern University Press, 1993.
Fiske, D.W. and S.R. Maddi (editors), Functions of Varied
Experience, The Dorsey Press, third impression, 1967.
Goldberg, A. and D. Robson, Smalltalk-80: the language,
Addison-Wesley, 1989.
Kay, A., Microelectronics and the Personal Computer, in: Scientific American, September 1977.
Kilov, H. and J. Ross, Information modeling: An
Object-Oriented Approach, Prentice-Hall, 1994.
Maltby, A., Sayer's Manual of Classification for
Librarians, André Deutsch, reprint of fifth edition, 1978.
Martin, J., Principles of Object-Oriented Analysis and
Design, Prentice-Hall, 1993.
Taylor, D.A., Object-Oriented Technology: A Manager's
Guide, Addison-Wesley, 1990.
———, Object-Oriented Information Systems: Planning and
Implementation, John Wiley and Sons, 1992.
Ter Bekke, J.H., Semantic Data Modeling in Relational
Environments, doctoral thesis TU Delft, 1991.
Tsichritzis, D.C. and F.H. Lochovsky, Data Models,
Prentice-Hall, 1982.
Wiener, N., The Human Use of Human Beings: Cybernetics
and Society, Doubleday, updated edition, 1954, original edition 1950.
Williamson, R.C., P.G. Swingle and S.S. Sargent, Social
Psychology, Peacock, 1982.
Wisse, P.E., Exploitatie van Documentaire Technieken, in: Overheidsdocumentatie, nr 1, January 1988.
———, Aspecten en Fasen, Information Dynamics,
1991.
———, Objecten: Volgehouden Inkapseling, in: Infomeel,
nr 14, January 1994.
———, De Kwaliteit van Objectgerichtheid is Subjectief, in: OT Magazine, nr 1, February 1994.
———, Aspecten van Objecttechnologie (Aspects of Object Technology), in: OT Magazine, nr 9/10, december 1994.
Wittgenstein, L., Philosophical Investigations,
The Macmillan Company, third edition, second impression, 1968 (original edition
1953).
© 1991-1999, web edition 2001.
Pieter Wisse is president of Information Dynamics (Netherlands, Voorburg). This paper has been published previously, in English, in his book Informatiekundige ontwerpleer (Ten Hagen Stam, 1999) with all other content written in Dutch.